机器学习入门02
今天继续进行机器学习的入门,主题是线性回归。
线性回归(Linear Regression)
线性回归是一种 用于找出各个变量之间的关系的统计技术。在机器学习中线性回归模型会找出 功能和 label 之间的关联。
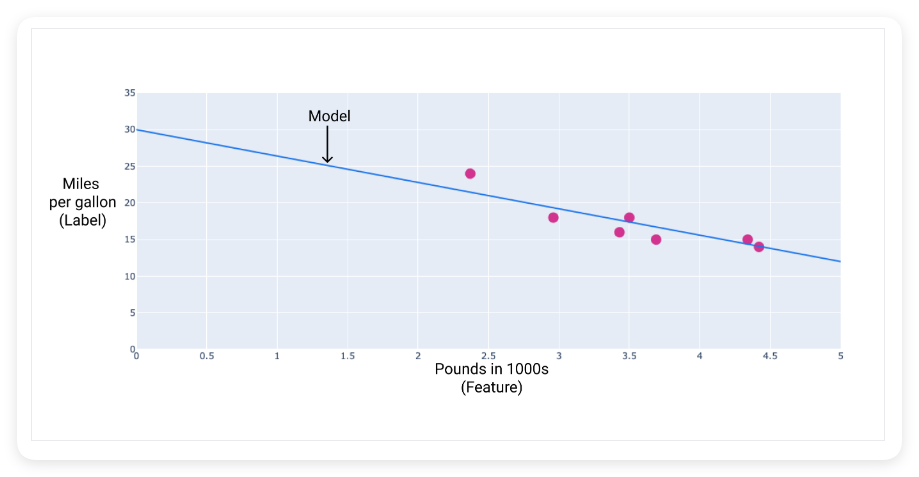
例如,假设我们要预测汽车的燃油效率(以英里/英里为单位) 根据汽车的重量确定加仑,我们有以下数据集:
| 干磷(功能) | 英里/加仑(标签) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
如果我们绘制这些点,通过这些点绘制一条最适合的直线来创建自己的模型,就会得到以下图表:
线性回归方程(Linear Regression Equation)
用代数术语来说,模型的定义为:
\[y = mx + b\]
其中:
- y 表示每加仑英里数,即我们想要预测的值
- m 是直线的斜率
- x 是磷,即我们的输入值
- b 为 y 轴截距
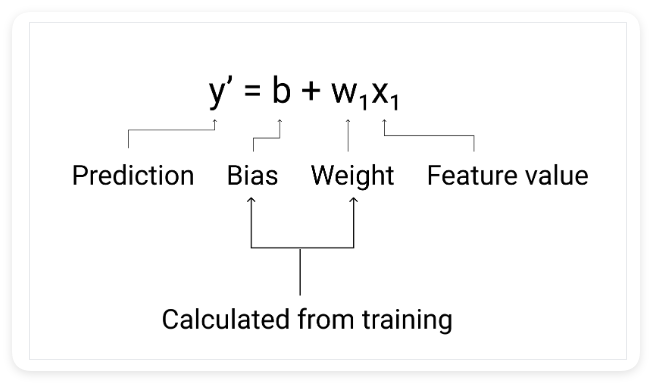
在机器学习中,我们编写线性回归模型的方程式如下所示:
\[y' = b + w_1x_1\]
其中:
- y' 是预测标签,即输出
- b 是偏差(Bias)模型。偏差与代数中y截距的概念相同直线方程。在机器学习中,偏差有时称为 w₀。偏差是一个模型的参数,而且是在训练期间计算的
- w₁ 是权重(Weight)功能。权重与代数中斜率 m 的概念相同直线方程。权重为参数,是在训练期间计算的
- x₁ 是一项特征(Feature),即输入
在训练期间,模型会计算可产生最佳结果的权重和偏差模型。
在我们的示例中,通过终止的线性计算得到:
- 偏差为 30 (对应 y 轴截距)
- 权重为 -3.6 (直线的斜率)
因此,我们的模型可以表示为:
\[y' = 30 + (-3.6)(x_1)\]
现在我们就可以用这个模型进行预测了。例如,对于一辆重量为 4000 磷的汽车,我们可以预测其燃油效率:
\[y' = 30 + (-3.6)(4.0) = 30 - 14.4 = 15.6\]
预测结果表明这辆汽车的燃油效率约为每加仑15.6英里。
具有多个特征的模型(Models with Multiple Features)
虽然本文中的示例仅使用了一项功能(即重量级汽车的特征),但更复杂的模型可能依赖于多种特征,每个特征都有单独的权重(w₁、w₂ 等)。例如,一个模型可以写为:
\[y' = b + w_1x_1 + w_2x_2 + w_3x_3 + w_4x_4 + w_5x_5\]
例如,预测汽油里程的模型可以额外使用特征如:
- 发动机排量 (Displacement)
- 加速性能 (Acceleration)
- 汽缸数 (Number of cylinders)
- 马力 (Horsepower)
此模型的编写方式如下图所示:
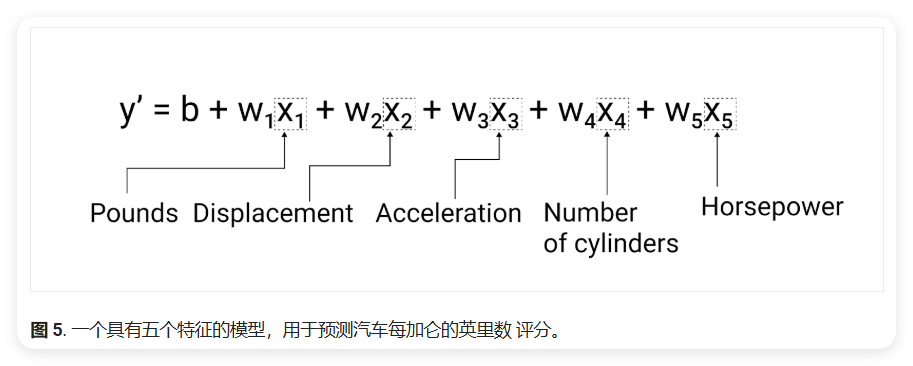
在这个模型中:
- x₁ 代表重量 (Pounds)
- x₂ 代表排量 (Displacement)
- x₃ 代表加速性能 (Acceleration)
- x₄ 代表汽缸数 (Number of cylinders)
- x₅ 代表马力 (Horsepower)
每个特征(x)都有其对应的权重(w),这些权重在训练过程中被优化,以获得最准确的预测结果。
线性回归:损失(Loss)
损失是一个数值指标,用于描述模型的预测有多大偏差。损失函数用于衡量模型预测与实际标签之间的距离。训练模型的目标是尽可能降低损失,将其降至最低值。
在下图中,可以将损失可视化为从数据点指向模型的箭头。箭头表示模型的预测结果与实际值之间的差距。
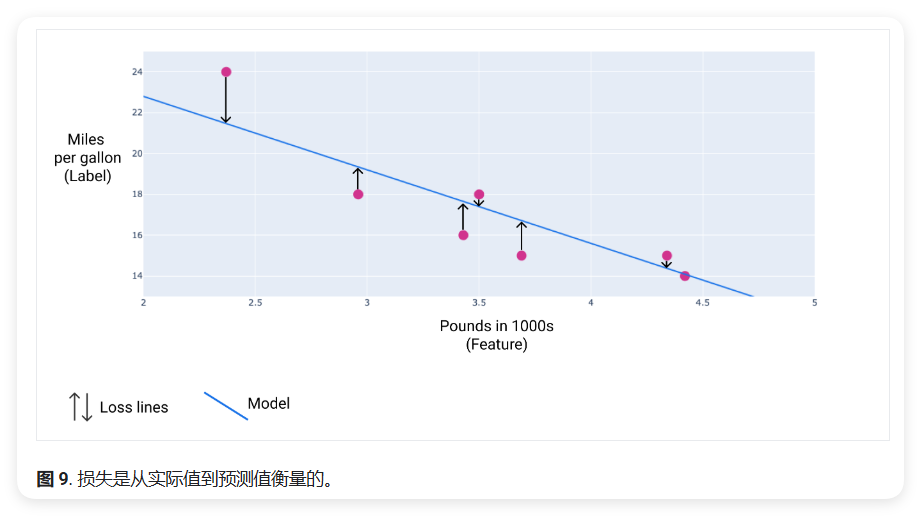
损失距离(Loss Distance)
在统计学和机器学习中,损失函数用于衡量预测值与实际值之间的差异。损失函数侧重于值之间的距离,而不是方向。例如,如果模型预测值为 2,但实际值为 5,我们并不关心损失为负值(5 - 2 = -3)。我们关心的是这两个值之间的距离为 3。因此,所有用于计算损失的方法都会移除符号。
移除此标记的两种最常用方法如下:
计算实际值与预测值之间的差值的绝对值: \[L1 = |y - y'|\]
将实际值与预测值之间的差值平方: \[L2 = (y - y')^2\]
损失类型
在线性回归中,有四种主要的损失函数,如下表所示。

L₁ 损失函数和 L₂ 损失函数(或 MAE 和 MSE)之间的功能差异在于平方。当预测值与标签之间的差异较大时,平方会使损失变得更大。当差异较小(小于 1)时,平方会使损失更小。
当处理多个示例时,我们通常会对所有示例的损失进行平均,无论是使用 MAE 还是 MSE。
- MSE (Mean Square Error):均方误差
- 计算公式:MSE = (Σ(预测值 - 实际值)²) / n
- RMSE (Root Mean Square Error):均方根误差
- 计算公式:RMSE = √MSE
- 即MSE开平方根
损失计算示例
使用之前的最佳拟合直线,我们将计算单个示例的 L₂ 损失。从最优拟合直线中,我们得到了权重和偏差的以下值:
- Weight: -3.6
- Bias: 30
如果模型预测重 2,370 磅的汽车每加仑可行驶 21.5 英里,但实际每加仑可行驶 24 英里,我们将按如下方式计算 L₂ 损失:
\[L_2 = (y - y')^2 = (24 - 21.5)^2 = (2.5)^2 = 6.25\]
在此示例中,该单个数据点的 L₂ 损失为 6.25。
选择损失函数(Choosing Loss Functions)
确定使用 MAE 还是 MSE 可能取决于数据集以及希望处理特定预测的方式。数据集中的大多数特征值通常属于一个特定范围,例如:
- 汽车通常在 2,000 到 5,000 磅之间
- 每加仑汽油能行驶的英里数介于 8 到 50 英里之间
- 重 8,000 磅的汽车或每加仑汽油能行驶 100 英里的汽车都超出了典型范围,会被视为离群值(Outliers)
离群值处理
离群值还可以指模型的预测与真实值之间的差距。例如:
- 3,000 磅的车重属于典型的车重范围
- 每加仑 40 英里的油耗属于典型的油耗范围
- 但是,对于每加仑 40 英里的 3,000 磅汽车,如果模型预测每加仑能行驶 18 到 20 英里,这个预测结果会认为是离群值
损失函数的选择
选择最佳损失函数时,考虑希望模型如何处理离群值:
- MSE 会使模型更接近离群值
- MAE 则不会
- 与 L₁ 损失函数相比,L₂ 损失函数对离群值的惩罚更高
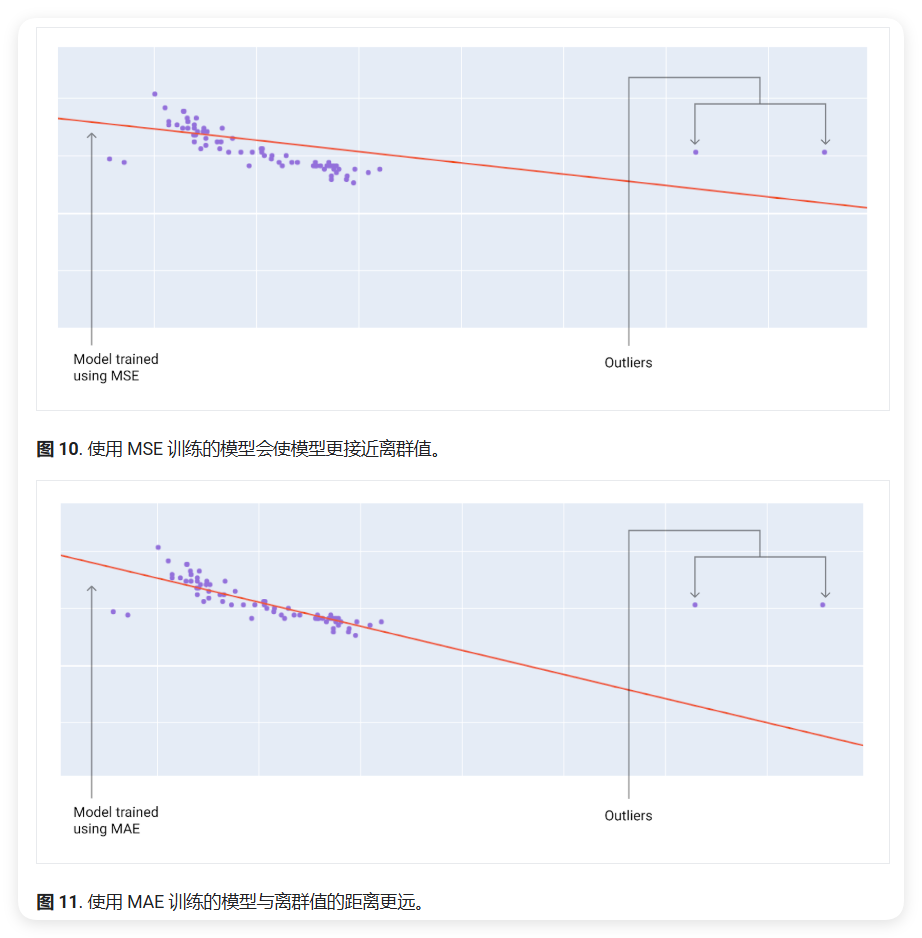
例如,下图片显示了使用 MAE 训练的模型和使用 MSE 训练的模型的比较。红线表示将用于进行预测的完全训练好的模型:
- 离群值更接近使用 MSE 训练的模型
- 离群值对使用 MAE 训练的模型影响较小
线性回归:梯度下降(Gradient Descent)
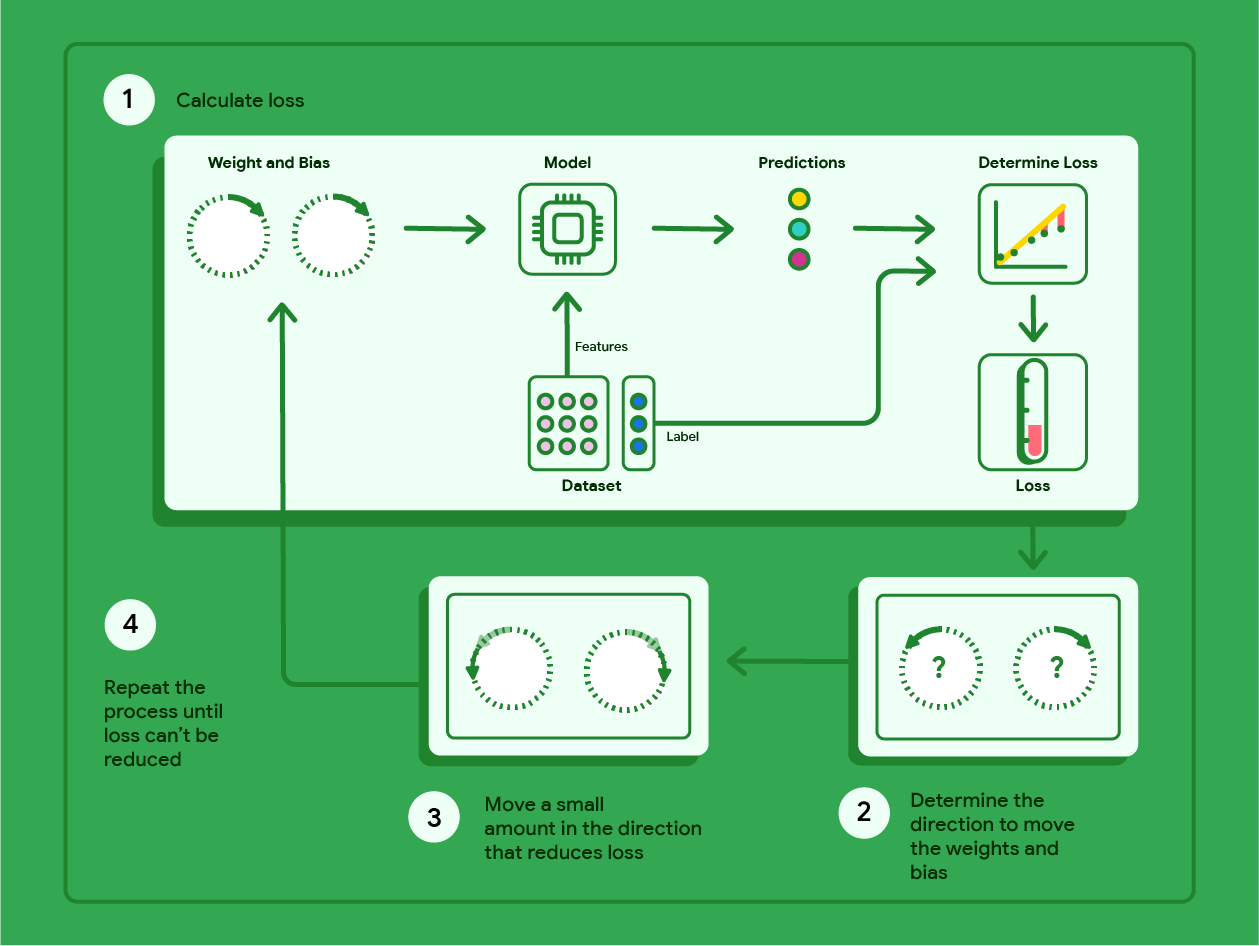
梯度下降法是一种数学技术,能够以迭代方式找出权重和偏差,从而生成损失最低的模型。梯度下降法会针对用户指定的多次迭代重复以下过程,以找到最佳权重和偏差。
模型开始训练时使用接近于零的随机权重和偏差,然后重复以下步骤:
- 使用当前权重和偏差计算损失。
- 确定用于减少损失的权重和偏差的移动方向。
- 将权重和偏差值在可减少损失的方向上稍微移动。
- 返回第 1 步并重复此过程,直到模型无法进一步降低损失。
下图概述了梯度下降法为找出损失最低的模型权重和偏差所执行的迭代步骤。
梯度下降实例
示例数据集
我们使用一个包含 7 个示例的小型数据集来演示梯度下降,这些示例分别对应汽车的重量(以磅为单位) 和每加仑行驶里程数:
| 以千计的英磅 (特征) | 每加仑英里 (标签) |
|---|---|
| 3.5 | 18 |
| 3.69 | 15 |
| 3.44 | 18 |
| 3.43 | 16 |
| 4.34 | 15 |
| 4.42 | 14 |
| 2.37 | 24 |
梯度下降步骤
1. 初始化模型参数
模型会先将权重和偏差设为零,然后开始训练: 1
2
3Weight: 0
Bias: 0
y = 0 + 0(x₁)
2. 计算初始损失
使用当前的模型参数计算 MSE 损失: \[Loss = \frac{(18-0)^2 + (15-0)^2 + (18-0)^2 + (16-0)^2 + (15-0)^2 + (14-0)^2 + (24-0)^2}{7}\] \[Loss = 303.71\]
3. 计算梯度
我们需要计算损失函数相对于权重和偏差的导数。预测函数定义为: \[f_{w,b}(x) = (w * x) + b\]
MSE 损失函数为: \[\frac{1}{M} \sum_{i=1}^M (f_{w,b}(x_{(i)}) - y_{(i)})^2\] 其中 \(i\) 表示第 \(i\) 个训练示例,\(M\) 表示示例数量。
权重的梯度
权重的导数计算: \[\frac{\partial}{\partial w} \frac{1}{M} \sum_{i=1}^M (f_{w,b}(x_{(i)}) - y_{(i)})^2\]
求值结果: \[\frac{1}{M} \sum_{i=1}^M (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)}\]
当权重和偏差为零时,计算得到斜率为 -119.7。
偏差的梯度
偏差的导数计算: \[\frac{\partial}{\partial b} \frac{1}{M} \sum_{i=1}^M (f_{w,b}(x_{(i)}) - y_{(i)})^2\]
求值结果: \[\frac{1}{M} \sum_{i=1}^M (f_{w,b}(x_{(i)}) - y_{(i)}) * 2\]
当权重和偏差为零时,计算得到斜率为 -34.3。
4. 更新参数
向负斜率方向移动一小步(学习率设为 0.01):
\[New\ weight = old\ weight - (0.01 * weight\ slope)\] \[New\ bias = old\ bias - (0.01 * bias\ slope)\]
第一次迭代的计算: \[New\ weight = 0 - (0.01) * (-119.7) = 1.2\] \[New\ bias = 0 - (0.01) * (-34.3) = 0.34\]
迭代结果
重复上述步骤六次后,得到以下结果:
| 迭代 | 权重 | 偏差 | 损失 (MSE) |
|---|---|---|---|
| 1 | 0 | 0 | 303.71 |
| 2 | 1.2 | 0.34 | 170.67 |
| 3 | 2.75 | 0.59 | 67.3 |
| 4 | 3.17 | 0.72 | 50.63 |
| 5 | 3.47 | 0.82 | 42.1 |
| 6 | 3.68 | 0.9 | 37.74 |
收敛过程
在训练过程中,损失值会随着迭代次数的增加而不断降低。当损失值趋于稳定,不再显著下降时,我们就说模型达到了收敛状态。此时继续训练,损失值可能会出现小幅波动,但整体保持稳定。
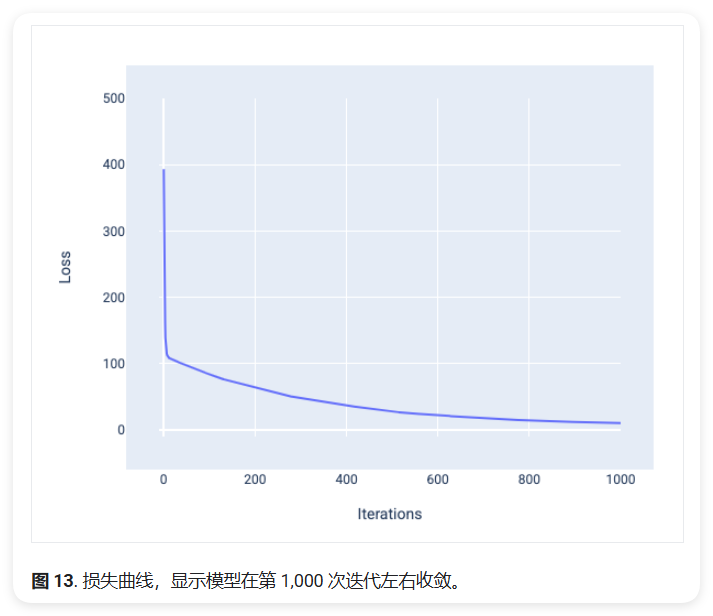
损失曲线
损失曲线是观察模型收敛情况的重要工具。它展示了损失值随迭代次数的变化趋势:
典型的损失曲线有以下特点:
- 初期阶段: 损失值快速下降
- 中期阶段: 下降速度逐渐放缓
- 后期阶段: 趋于平稳,表明模型接近收敛
凸函数与最小值
线性回归模型的损失函数是一个凸函数,这意味着它只有一个全局最小值。下图展示了一个单特征模型的损失函数表面:
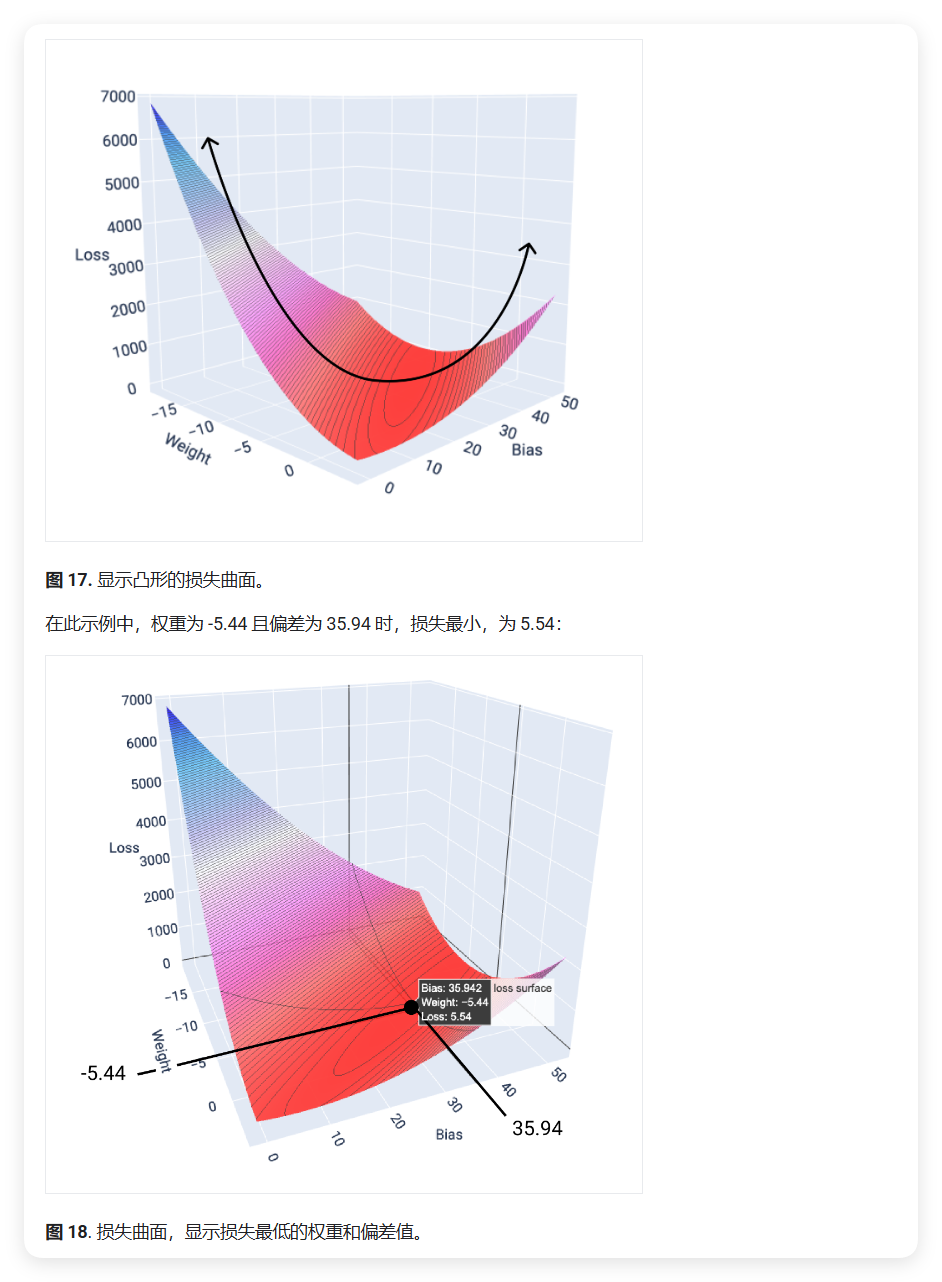
- x轴: 权重 (Weight)
- y轴: 偏差 (Bias)
- z轴: 损失值 (Loss)
这种凸形状保证了:
- 梯度下降一定能找到最小损失点
- 不会陷入局部最小值
需要注意的是:
- 模型通常找到的是接近最小值的点,而不是精确的最小值
- 最小损失点并不意味着零损失,而是在当前数据下能达到的最优解
线性回归:超参数(Hyperparameters)
超参数是用于控制训练过程的变量。常见的超参数包括:
- 学习速率 (Learning Rate)
- 批量大小 (Batch Size)
- 纪元 (Epoch)
与模型参数(如权重和偏差)不同,超参数是在训练前设置的控制值,而不是在训练过程中学习得到的值。
学习速率(Learning Rate)
学习速率决定了每次梯度下降时模型参数的调整步长。它直接影响模型的训练效果:
- 学习速率过低:
- 模型收敛速度慢
- 需要更多迭代才能达到最优解
- 训练时间较长
- 学习速率过高:
- 可能导致模型无法收敛
- 参数更新幅度过大,在最优解附近来回震荡
- 难以找到最优解
选择合适的学习速率很重要: - 需要在训练速度和稳定性之间取得平衡 - 通常从一个较小的值开始尝试(如0.01) - 根据训练效果进行调整
例如:如果梯度为2.5,学习速率为0.01,则参数的更新步长为0.025。理想的学习速率应该使模型在合理的迭代次数内收敛。
将学习速率翻倍可能会减慢训练速度。 此声明是正确的。将学习率翻倍可能会导致学习率过大,从而导致权重"跳来跳去",增加收敛所需的时间。
批量大小 (Batch Size)
批量大小是一个超参数,表示每次更新模型参数时使用的训练样本数量。虽然理论上可以在每次迭代时使用所有训练样本,但当数据集很大时(如包含数十万至数百万个样本),这种方法在计算上是不实际的。
为了解决这个问题,有两种常用的梯度下降方法:
随机梯度下降法 (SGD, Stochastic Gradient Descent)
- 每次迭代只使用一个随机样本(批量大小为1)
- 优点:
- 计算速度快
- 能够跳出局部最优解
- 缺点:
- 参数更新波动较大
- 收敛过程不稳定
下图展示了使用SGD训练时的损失曲线:
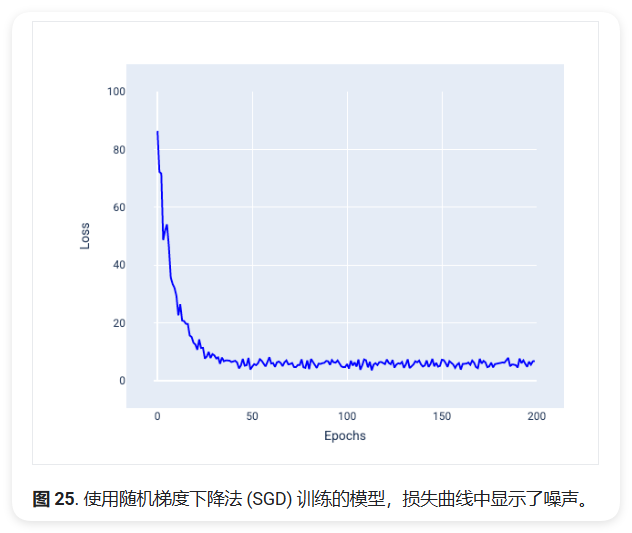
可以看到,虽然整体趋势是下降的,但曲线呈现出明显的波动。这种波动不仅出现在训练初期,在接近收敛时也会存在。
小批量随机梯度下降法 (mini-batch SGD)
- 是完整批量梯度下降和SGD的折中方案
- 每次使用一小批样本(批量大小通常在1到N之间,N为总样本数)
- 特点:
- 对每个批次计算平均梯度
- 参数更新更稳定
- 计算效率较高
批量大小的选择:
- 批量较小时:行为类似于SGD,更新波动大但计算快
- 批量较大时:行为类似于完整批量梯度下降,更新稳定但计算慢
- 需要在计算效率和训练稳定性之间找到平衡
在训练模型时,噪声并不总是不良特征。适当的噪声可以帮助模型更好地泛化,这一点在神经网络的权重和偏差优化中尤为重要。
纪元 (Epoch)
纪元表示模型完整处理训练集一次的过程。例如,对于包含1,000个样本的训练集,如果批量大小为100,则需要10次迭代(iterations)才能完成一个纪元。
训练通常需要多个纪元,因为模型需要多次处理训练集中的所有样本才能达到较好的效果。纪元数是在训练开始前设置的超参数。一般来说,纪元数越多,模型拟合得越好,但训练时间也越长。
下表比较了不同批处理方式对参数更新次数的影响:
| 批处理类型 | 参数更新频率 |
|---|---|
| 完整批次 | 每个纪元更新一次。例如:1000个样本,训练20个纪元,总共更新20次 |
| 随机梯度下降 | 每个样本更新一次。例如:1000个样本,训练20个纪元,总共更新20,000次 |
| 小批量梯度下降 | 每个批次更新一次。例如:1000个样本,批量大小100,训练20个纪元,总共更新200次 |
从上表可以看出:
- 完整批次:参数更新最少,但每次计算量大
- 随机梯度下降:参数更新最频繁,但可能不稳定
- 小批量梯度下降:在更新频率和计算效率之间取得平衡
线性回归:编程练习
Part 1 - Setup Exercise
在机器学习项目中,通常需要以下几类Python库来帮助我们完成不同的任务:
数据处理库
1 | import numpy as np # 数值计算 |
- NumPy (np)
- 用于处理数值数据的基础库
- 提供高效的数组操作
- 常用功能示例:
1
2
3
4
5
6
7
8# 创建数组
arr = np.array([1, 2, 3, 4, 5])
# 基本运算
arr + 1 # [2, 3, 4, 5, 6]
arr * 2 # [2, 4, 6, 8, 10]
# 统计运算
arr.mean() # 平均值
arr.max() # 最大值
- Pandas (pd)
- 用于处理表格数据的高级库
- 提供DataFrame数据结构(类似Excel表格)
- 常用功能示例:
1
2
3
4
5
6
7
8
9# 创建数据表
df = pd.DataFrame({
'重量': [2.0, 2.4, 1.5],
'里程': [18, 15, 18]
})
# 读取CSV文件
df = pd.read_csv('data.csv')
# 基本统计
df.describe() # 显示统计信息
机器学习库
1 | import keras # 深度学习框架 |
Keras - 用于构建和训练深度学习模型的高级框架 -
提供简单易用的API - 常用功能示例: 1
2
3
4
5
6# 构建简单的神经网络
model = keras.Sequential([
keras.layers.Dense(1, input_shape=[1])
])
# 编译模型
model.compile(optimizer='sgd', loss='mse')
数据可视化库
1 | import plotly.express as px |
- Plotly (px, go)
- 用于创建交互式图表
- 支持多种图表类型
- 常用功能示例:
1
2
3
4# 创建散点图
fig = px.scatter(df, x='重量', y='里程')
# 显示图表
fig.show()
- Seaborn (sns)
- 基于Matplotlib的统计可视化库
- 提供美观的默认样式
- 常用功能示例:
1
2# 创建散点图
sns.scatterplot(data=df, x='重量', y='里程')
在实际项目中,这些库通常会一起使用: 1. 使用Pandas读取和处理数据 2. 用NumPy进行数值计算 3. 使用Keras构建和训练模型 4. 用Plotly或Seaborn可视化结果
加载数据
1 | # 从网络加载芝加哥出租车数据集 |
这行代码使用pandas的read_csv()函数从网络下载并读取CSV文件。这个数据集包含了芝加哥出租车的行程信息。
选择特定列
1 | # 选择需要的列创建新的DataFrame |
这里我们从原始数据集中选择了6个重要特征:
- TRIP_MILES:行程距离
- TRIP_SECONDS:行程时长
- FARE:车费金额
- COMPANY:出租车公司
- PAYMENT_TYPE:支付方式
- TIP_RATE:小费比例
查看数据信息
1 | # 打印数据集基本信息 |
这段代码做了两件事:
- 打印数据集的总行数
- 显示数据集的前200行,帮助我们了解数据的基本结构
Part 2 - Dataset Exploration
基本统计信息:
1 | # 查看数值列的统计信息 |
输出结果类似: 1
2
3
4
5
6
7
8
9 TRIP_MILES FARE
count 4.0 5.0 # 非空值数量
mean 2.75 13.0 # 平均值
std 1.04 4.7 # 标准差
min 1.50 8.0 # 最小值
25% 2.25 10.0 # 25%分位数
50% 2.75 12.0 # 中位数
75% 3.25 15.0 # 75%分位数
max 4.00 20.0 # 最大值
1 | # 查看数据类型 |
输出结果: 1
2
3
4
5
6
7Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 TRIP_MILES 4 non-null float64 # 4条非空数据,浮点型
1 FARE 5 non-null int64 # 5条非空数据,整数型
2 PAYMENT_TYPE 5 non-null object # 5条非空数据,字符串型
3 COMPANY 5 non-null object # 5条非空数据,字符串型
缺失值检查:
1 | # 检查缺失值 |
输出结果: 1
2
3
4TRIP_MILES 1 # TRIP_MILES列有1个缺失值
FARE 0 # FARE列没有缺失值
PAYMENT_TYPE 0 # PAYMENT_TYPE列没有缺失值
COMPANY 0 # COMPANY列没有缺失值
分类变量分析:
1 | # 查看支付方式的种类 |
相关性分析:
1 | # 计算行程里程和车费的相关性 |
输出结果: 1
2
3 TRIP_MILES FARE
TRIP_MILES 1.000000 0.850123 # 正相关,说明里程越长,费用越高
FARE 0.850123 1.000000
在这一步中,我们将使用相关矩阵(Correlation Matrix)来识别与标签值相关性良好的特征。相关值具有以下含义: 1. 完全正相关(Perfect Positive Correlation):1.0 - 定义:当一个属性(attribute)上升时,另一个属性也上升 - 例如:学习时间与考试成绩的关系 2. 完全负相关(Perfect Negative Correlation):-1.0 - 定义:当一个属性上升时,另一个属性下降 - 例如:商品价格与销售量的关系 3. 无相关性(No Correlation):0.0 - 定义:两列之间不存在线性关系(Linear Relationship) - 例如:学生的身高与考试成绩的关系
一般来说,相关值(Correlation Value)的绝对值越大,该特征(Feature)的预测能力就越强
使用pairplot进行多变量关系可视化,这段代码将创建一个3x3的图表矩阵:
1 | sns.pairplot(training_df, |
Part 3 - Train Model
在这部分,我们将实现一组用于模型训练和可视化的函数。这些函数可以帮助我们可视化训练过程、展示模型预测结果和分析模型性能。
1. 可视化函数实现
1 | def make_plots(df, feature_names, label_name, model_output, sample_size=200): |
模型训练函数实现
1 | def build_model(my_learning_rate, num_features): |
运行训练实验
1 | # 设置超参数 |
Part 4 - Validate Model
1 | def format_currency(x): |
执行模型预测
1 | # 使用训练好的模型进行预测 |
以上是线性回归的基础内容,后续的内容请看下一篇博客。