机器学习入门08
今天继续进行机器学习的入门,主要介绍数据集、泛化和过拟合相关的概念。
数据集(Datasets)、泛化(Generalization)和过拟合(Overfitting)
数据集的基本概念
数据集是机器学习模型训练的基础,它是一组示例的集合。数据通常以表格(如CSV)、日志文件或协议缓冲区等形式存储。无论采用何种格式,机器学习模型的效果都高度依赖于训练数据的质量。
数据集的关键特征
1. 数据类型
数据集可以包含多种类型的数据:
- 数值数据: 如温度、价格等连续值
- 分类数据: 如颜色、品牌等离散值
- 文本数据: 包括单词、句子和文档
- 多媒体数据: 图像、视频和音频
- 其他特殊类型数据
2. 数据数量
训练样本数量的一般原则: - 至少比可训练参数多一到两个数量级 - 数据量越大,模型效果通常越好 - 具体需求取决于问题复杂度: - 简单问题:几十个样本可能足够 - 复杂问题:可能需要数万个样本
3. 数据质量与可靠性
高质量数据的特征: - 标签准确性高 - 特征信息合理完整 - 具有良好的代表性
评估数据可靠性需要考虑: - 人工标注的错误率 - 特征是否包含有效信息 - 数据是否具有充分代表性
4. 数据完整性与插值
处理不完整数据的策略: 1. 删除不完整样本(当完整样本充足时) 2. 删除缺失严重的特征 3. 使用插值填充缺失值
插值方法: - 使用平均值或中位数 - 使用Z得分(标准化后的0值) - 其他统计或机器学习方法
数据集标签(Labels)
1. 标签类型
直接标签: - 与预测目标完全对应 - 例如:预测自行车拥有情况时的"bicycle owner"标签
代理标签: - 与预测目标相关但不完全对应 - 例如:使用杂志订阅信息预测自行车拥有情况
2. 人工生成数据
优势: - 可处理复杂任务 - 保证标准一致性
劣势: - 成本高 - 存在人为错误
不平衡数据集
不平衡数据集中各类别样本数量差异显著。根据少数类占比,可分为:
| 少数类占比 | 不平衡程度 |
|---|---|
| 20-40% | 温和 |
| 1-20% | 一般 |
| <1% | 极端 |
例如:医疗诊断数据中,患病样本(阳性)通常远少于健康样本(阴性)。
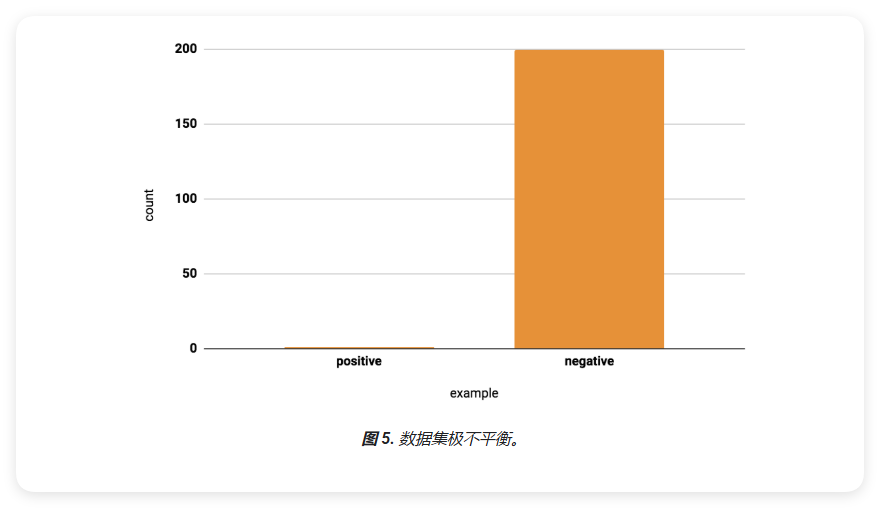
处理不平衡数据集的方法: 1. 过采样少数类 2. 欠采样多数类 3. 使用合成样本 4. 调整类别权重
权重调整方法
权重调整是处理不平衡数据集的一种有效方法。主要步骤如下:
- 下采样(Downsample): 从多数类中随机抽取部分样本
- 增加权重(Upweight): 对下采样后的样本增加权重值
权重计算公式:
\[ 样本权重 = 原始权重 \times 下采样因子 \]
例如:如果对多数类进行10倍下采样(即只保留1/10的样本),则这些样本的权重应该设为原来的10倍,以保持总体权重不变。
这种方法的优势在于: - 减少了训练数据量,提高训练效率 - 通过权重调整保持了原始数据的分布特性 - 有助于减小预测偏差
注意:选择合适的评估指标对于不平衡数据集尤为重要,不能仅依赖准确率。
重新平衡比率
在处理不平衡数据集时,通过缩减和增加多少数据来重新平衡数据集,需要考虑以下几个因素:
- 批次大小: 每个训练批次的样本数量
- 不平衡比率: 多数类与少数类样本数量的比值
- 训练集示例数: 整个训练集中的样本总数
需要注意的是: - 每个批次必须包含足够的少数类示例 - 批处理大小应该是不平衡比率的倍数 - 例如:如果不平衡比率为100:1,则批次大小至少应为500,以确保每个批次中包含足够的少数类样本
理想情况下,每个批次都应包含多个少数类示例。如果批处理不包含足够的少数类样本,训练效果可能会非常差。
数据集拆分
在机器学习项目中,我们需要对模型进行充分的测试以确保其准确性和泛化能力。为此,通常需要将原始数据集拆分成不同的子集。
基本数据集划分
数据集通常会被划分为以下部分:
- 训练集(Training Set):
- 用于模型的训练和学习
- 通常占据数据集的大部分
- 测试集(Test Set):
- 用于评估训练好的模型性能
- 包含模型从未见过的数据

注意:测试数据必须是模型训练过程中从未使用过的数据,这样才能真实评估模型的泛化能力。
三分法数据集划分
更好的做法是将数据集划分为三个部分:
- 训练集(Training Set):
- 用于模型的训练和学习
- 通常占据数据集的最大部分
- 验证集(Validation Set):
- 用于评估模型训练过程中的效果
- 帮助调整模型参数和超参数
- 测试集(Test Set):
- 用于最终评估模型性能
- 只在模型完全训练好后使用一次

模型开发流程
标准的机器学习模型开发流程如下:
- 在训练集上训练模型
- 在验证集上评估模型效果
- 根据验证结果调整模型
- 重复以上步骤直到达到满意的效果
- 最后在测试集上确认最终结果
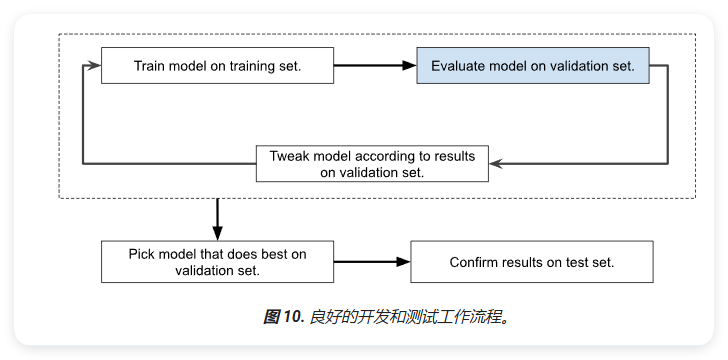
注意:在训练集中转换特征时,必须在验证集和测试集和训练集中进行相同的转换。
数据集使用注意事项
- 避免数据泄露:
- 确保验证集和测试集中的数据在训练过程中完全未被使用
- 特征工程和数据预处理步骤要在划分数据集之后进行
- 防止数据"磨损":
- 验证集和测试集在反复使用后会"磨损"
- 过度使用同样的数据来做出超参数设置或其他模型改进的决策,会导致模型对这些数据的过拟合
- 建议定期收集新数据来"刷新"测试集和验证集
- 最佳实践:
- 保持数据集的独立性
- 定期更新数据集
- 避免测试集的重复使用
- 在条件允许的情况下,收集更多新数据
测试集的其他问题
如前面所述,重复示例可能会影响模型评估。特别是在将数据集分为训练集、验证集和测试集后,请删除验证集或测试集中与训练集中的示例重复的所有示例。对模型进行公平测试的唯一方法是使用新示例,而不是重复示例。
案例分析
例如,假设有一个模型,它使用主题行、电子邮件正文和发件人的电子邮件地址作为特征来预测某封电子邮件是否为垃圾邮件。假设您将数据划分为训练集和测试集,按80-20的比例进行拆分。训练完成后,该模型在训练集和测试集上的准确率均达到99%。您可能预计测试集的精确率会较低,因此您再次查看数据,发现测试集中的许多示例与训练集中的示例重复。问题在于,您在拆分数据之前,忘记从输入数据库中清除同一垃圾邮件的重复条目。您无意中使用了部分测试数据进行训练。
测试集和验证集的要求
总而言之,一组好的测试集或验证集应满足以下所有条件:
- 足够大:能够得出具有统计显著性的测试结果。
- 能代表整个数据集:换言之,挑选的测试集的特征应该与训练集的特征相同。
- 代表模型在真实业务场景中会遇到的真实数据。
- 训练集中没有重复的示例。
数据集:转换数据(Transforming Data)
机器学习模型只能基于浮点值进行训练。不过,许多数据集特征本身不是浮点值。因此,机器学习的一个重要部分是将非浮点特征转换为浮点表示法。
字符串特征转换
例如,假设 street names 是地图项,大多数街道名称都是字符串,例如"Broadway"或"Vilakazi"。您的模型无法使用"Broadway"进行训练,因此必须将"Broadway"转换为浮点数。"分类数据"模块介绍了具体操作。
此外,您还应转换大多数浮点地图项。此转换过程称为标准化,可将浮点数转换为受限范围,从而改进模型训练。"数值数据"模块介绍了如何执行此操作。
对数据进行采样(如果数据量过多)
有些组织拥有丰富的数据。如果数据集包含的示例过多,您必须选择一组子集进行训练。请尽可能选择与模型预测最相关的子集。
包含个人身份信息的过滤条件示例
优质数据集会省略包含个人身份信息(PII)的示例。此政策有助于保护隐私,但可能会影响模型。
数据集:泛化(Generalization)
泛化是机器学习中的一个重要概念,指的是模型在未见过的数据上的表现。
过拟合(Overfitting)
过拟合是指创建的模型与训练集过于匹配(记忆),以致于模型无法根据新数据做出正确的预测。过拟合模型类似于在实验室中表现出色但在现实世界中毫无用处的发明。
提示:过拟合是机器学习中的常见问题,而非学术概念。
拟合(Fitting)、过拟合(Overfitting)和欠拟合(Underfitting)
模型必须能对新数据做出良好的预测。也就是说,您要创建一个能"拟合"新数据的模型。
如何所见,过拟合模型在训练集上可以做出出色的预测,但在新数据上做出的预测却不准确。欠拟合模型甚至无法对训练数据做出准确的预测。如果过拟合模型就像在实验室中表现出色但在现实世界中毫无用处的发明,那么欠拟合模型就像在实验室中表现不佳的产品。
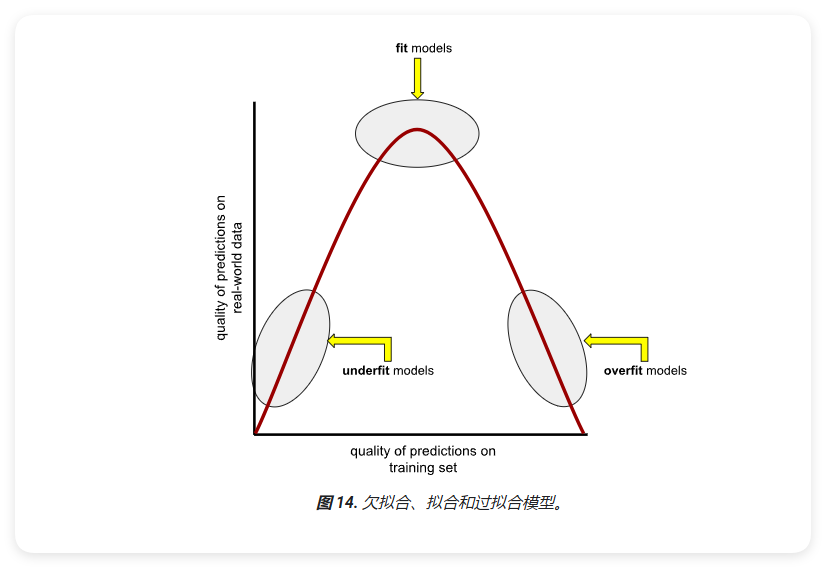
泛化与过拟合相反。也就是说,泛化能力强的模型可以对新数据做出良好的预测。您的目标是创建一个能够很好地泛化到新数据的模型。
检测过拟合
以下曲线可帮助您检测过拟合:
- 损失曲线
- 泛化曲线
损失曲线会将模型的损失与训练迭代次数绘制在图表中,显示两个或更多损失曲线的图表称为泛化曲线。以下泛化曲线展示了两个损失曲线:
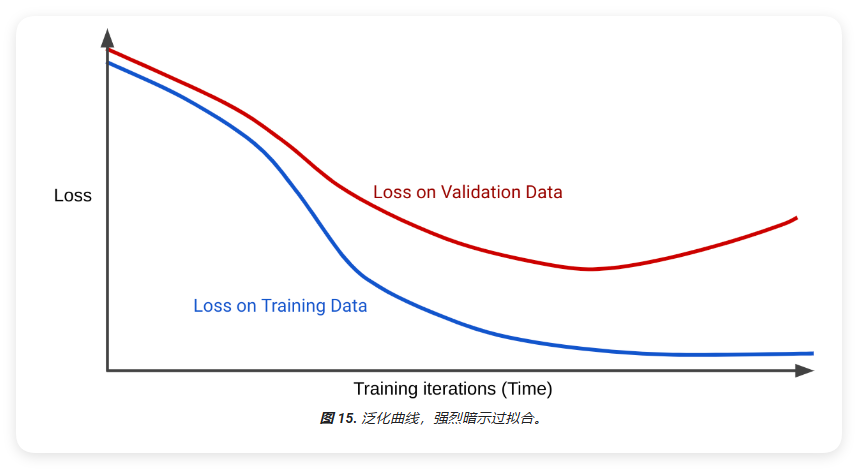
请注意,这两个损失曲线最初的行为类似,然后开始分叉。也就是说,经过一定次数的迭代后,训练集的损失会下降或保持稳定(收敛),但验证集的损失会增加。这表明模型过拟合。
相比之下,适合度较高的模型的泛化曲线会显示两个形状相似的损失曲线。
什么会导致过拟合?
一般来说,过拟合是由以下一种或两种问题导致的:
- 训练集不能完全代表真实数据(或验证集或测试集)。
- 模型过于复杂。
泛化条件
模型在训练集中进行训练,但真正检验模型价值的标准是它对新示例(尤其是真实数据)的预测效果如何。在开发模型时,测试集可用作真实数据的替代品。训练能够很好地泛化到新数据的模型,需要满足以下数据集条件:
- 示例必须独立且等概率分布,这是一种巧妙的方式,表示您的示例不能相互影响。
- 数据集是平稳的,这意味着数据集属不会随时间的推移而发生显著变化。
- 数据集分区具有相同的分布,也就是说,训练集中的示例在统计上与验证集、测试集和真实数据中的示例相似。
过拟合:模型复杂度(Model Complexity)
复杂模型在训练集中的表现通常优于简单模型。不过,简单的模型在测试集上的表现通常优于复杂的模型(这更重要)。
正则化
机器学习模型必须同时满足两个相互冲突的目标:
- 能很好地拟合数据。
- 尽可能简单地拟合数据。
为了让模型保持简单,一种方法是惩罚复杂的模型;也就是说,在训练过程中强制模型变得更简单。对复杂模型进行惩罚是一种正则化。
正则化示例:假设讲堂中的每位学生都有一个小时钟,发出的声音会让教授受到影响。每当教授的讲座变得过于复杂时,学生就会按下警报器。教授会因此而变小声,并将话简化讲得内容。教授会想到:"在简化时,我没有做到足够精确。"学生会反驳说:"唯一的目标是用简单易懂的方式解释,让自己能够理解。"渐渐地,这些警报器会训练教授讲授更简单的讲座,即使讲座内容不够精确也无妨。
损失和复杂性
到目前为止,本课程已表明训练的唯一目标是尽量减少损失;即:
minimize(loss)
如您所见,仅专注于最大限度地减少损失的模型往往会过拟合。更好的训练优化算法可最大限度地减少损失和复杂性的某种组合:
minimize(loss + complexity)
遗憾的是,损失和复杂性通常成反比。随着复杂性的增加,损失会降低,复杂性越低,损失就越大。您应找到一个合理的中间点,使模型对训练数据和真实数据都能做出良好的预测。也就是说,您的模型应在损失和复杂性之间找到合理的折衷。
过拟合:L2 正则化
L₂ 正则化是一种常用的正则化指标,其使用以下公式:
\[ L₂ regularization = w₁² + w₂² + ... + wₙ² \]
例如,下表显示了针对具有 6 个权重的模型计算 L₂ 正则化的过程:
| 值 | 平方值 |
|---|---|
| w₁ = 0.2 | 0.04 |
| w₂ = -0.5 | 0.25 |
| w₃ = 5.0 | 25.0 |
| w₄ = -1.2 | 1.44 |
| w₅ = 0.3 | 0.09 |
| w₆ = -0.1 | 0.01 |
| 总计 = 26.83 |
请注意,接近零的权重对 L₂ 正则化影响不大,但较大的权重可能会产生巨大影响。例如,在前面的计算中:
- 单个权重(w₃)约占总复杂度的 93%。
- 其他 5 个权重加起来只占总复杂度的 7% 左右。
L₂ 正则化会使权重趋近于 0,但绝不会使权重完全为零。
正则化率 (lambda)
如前所述,训练会尝试尽量减少损失和复杂性的某种组合:
minimize(loss + complexity)
模型开发者可以通过将复杂度值乘以一个称为"正则化率"的标量来调整复杂度对模型训练的总体影响。希腊字母 lambda 通常表示正则化率。
也就是说,模型开发者的目标是:
minimize(loss + λ complexity)
正则化率较高:
- 增强正则化的影响,从而降低过拟合的几率。
- 通常会生成具有以下特征的模型权重直方图:
- 正态分布
- 平均权重为 0
正则化率偏低:
- 降低正则化的影响,从而增加过拟合的可能性。
- 模型权重的直方图往往呈现平坦分布。
注意:将正则化率设为 0 可有效取消正则化。在这种情况下,训练仅专注于最大限度地减少损失,这会造成过拟合的风险。
选择正则化率
理想的正则化率可生成够好好地泛化到以前未见过的新数据的模型。遗憾的是,该理想值取决于数据,因此您必须手动或自动进行一些调优。
早停法:基于复杂性的正则化方法的替代方案
早停法是一种不涉及复杂性计算的正则化方法。相反,提前停止训练只是指在模型完全收敛之前结束训练。例如,当验证集的损失曲线开始增加(剧变实为正值)时,您可以结束训练。
虽然早停法通常会增加训练损失,但可以降低测试损失。
提前停止是一种快速的正则化方法,但很少能达到理想效果。生成的模型不太可能与使用理想正则化率彻底训练的模型一样出色。
在学习率和正则化率之间寻找平衡点
学习率和正则化率往往会朝相反的方向拉动权重。学习率较高时,权重通常会远离零;正则化率较高时,权重会趋近零。
如果正则化率相对于学习率较高,较小的权重往往会导致模型做出不准确的预测。相反,如果学习率相对于正则化率较高,则较大的权重往往会导致模型过拟合。
您的目标是在学习率和正则化率之间找到平衡点。这可能非常困难。最糟糕的是,找到这种难以捉摸的平衡后,您最终可能还需要更改学习率。而且,当您更改学习率时,您又必须找到理想的正则化率。