机器学习入门06
今天继续进行机器学习的入门,主题是处理数值数据。
处理数值数据 (Handling Numerical Data)
机器学习从业者需要花更多的时间来评估、清理和转换数据 而不是构建模型。
模型实际上会提取一个浮点值数组,称为特征向量(feature vector)。
请注意,机器学习模型与特征向量中的数据进行交互,而不是与数据集中的数据进行交互
特征工程(feature engineering)是机器学习中的重要环节,它将原始数据转换为更适合模型学习的形式。如图3所示,特征工程可以将原始数据集中的特征转换为模型可以更好学习的特征向量。
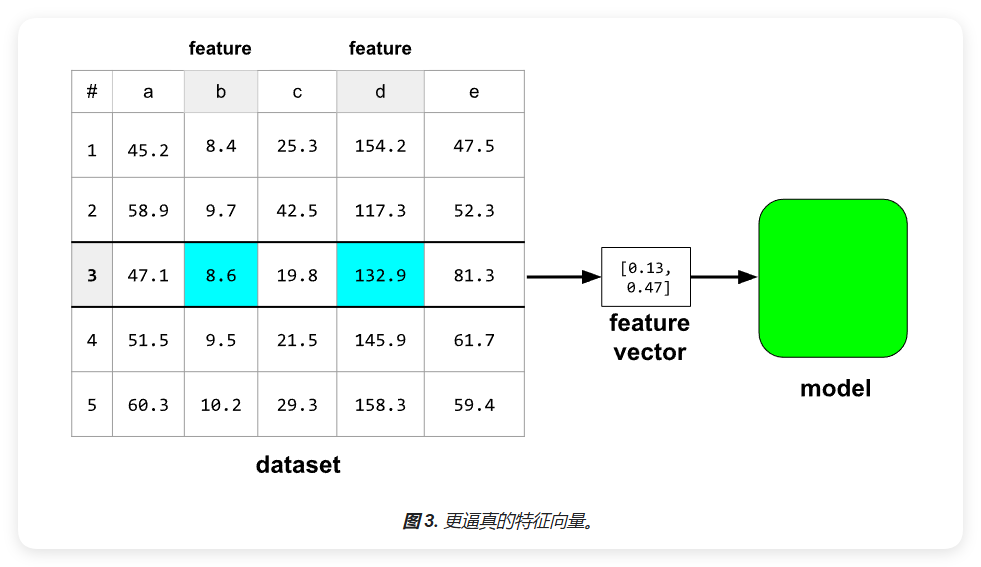
数值数据处理
在开始特征工程之前,我们需要对数据进行初步探索和分析。主要有两种方式:
- 数据直观查看
- 通过表格或图形直接观察数据
- 了解数据的基本结构和分布
- 发现明显的异常值或缺失值
- 统计信息分析
- 获取数据的统计特征
- 了解数据的分布情况
- 发现数据的潜在规律
数据可视化
数据可视化是发现数据中隐藏模式的重要工具:
- 可视化方法
- 散点图: 观察变量间的关系
- 直方图: 查看数据分布
- 箱线图: 识别异常值
- 使用pandas进行可视化
- 处理缺失数据
- 创建各类统计图表
- 进行数据转换和分析
数据统计分析
除了直观分析外,我们还需要通过数学方法评估潜在的特征和标签。主要包括以下基本统计信息:
- 集中趋势指标
- 平均值: 反映数据的平均水平
- 中位数: 反映数据的中心位置
- 离散程度指标
- 标准差: 反映数据的波动程度
- 四分位数: 第0、25、50、75和100百分位
- 第0个百分位是最小值
- 第50个百分位是中位数
- 第100个百分位是最大值
离群值检测
离群值是指与特征或标签中的大多数其他值相差显著的值。检测和处理离群值非常重要,因为:
- 影响模型训练
- 可能导致模型训练出现问题
- 影响模型的泛化能力
- 检测方法
- 使用四分位距离法
- 比较不同区间的差异
- 如果第0-25百分位区间差异与75-100百分位区间差异显著不同,则可能存在离群值
离群值可以分为以下两类:
- 错误数据
- 由于错误输入或设备故障产生
- 通常需要删除或修正
- 对模型训练没有实际价值
- 有效但异常的数据点
- 属于真实但罕见的情况
- 可能包含重要信息
- 需要谨慎处理
根据离群值的类型,采取不同的处理方法:
- 保留策略
- 如果离群值反映真实现象
- 可能有助于模型学习边界情况
- 注意极端值对模型的影响
- 处理方法
- 删除明显的错误数据
- 使用剪裁等特征工程技术
- 根据具体情况选择合适的处理方式
注意: 请勿过度依赖基本统计信息,异常中可能隐藏着有价值的数据模式。
数值数据标准化
通过标准化技术,我们可以将不同范围的特征转换到相似的尺度。这对模型训练非常重要。
标准化的必要性
以下是一个具体示例:
- 特征X的范围为154到24,917,482
- 特征Y的范围为5到22
这种范围差异巨大的情况会影响模型训练效果。标准化可以将这些特征转换到相似的范围(通常是0到1)。
标准化的优势
- 提高训练效率
- 避免模型在训练时出现"反弹"
- 提高收敛速度
- 可以使用Adagrad和Adam等优化器获得更好的效果
- 提高预测准确性
- 使模型对不同范围的特征有相同的敏感度
- 避免做出不切实际的预测
- 处理异常值
- 有助于避免"NaN陷阱"
- NaN(非数字)会在某些计算中产生
- 需要特别处理以避免传播
- 特征权重平衡
- 确保模型对每个特征给予合适的关注
- 防止范围较大的特征主导模型
- 提高小范围特征的影响力
警告: 如果在训练时对某特征进行了标准化,在预测时也必须对该特征进行相同的标准化处理。
常见标准化方法
- 线性缩放
- 将数据映射到指定范围
- 保持数据的相对关系
- 常用范围如[-1,1]或[0,1]
- Z分数标准化
- 基于均值和标准差
- 转换为标准正态分布
- 适用于近似正态分布的数据
- 目标扩缩
- 根据具体任务调整数据范围
- 考虑模型的特定需求
- 灵活调整标准化程度
- 剪裁技术
- 处理异常值和极端数据
- 确保数据落在合理范围内
- 不是标准的标准化方法,但可以辅助使用
建议: 根据数据特点和模型需求选择合适的标准化方法,必要时可以组合使用多种技术。
线性缩放(Min-Max标准化)
线性缩放是一种常用的标准化方法,它可以将数据从原始范围转换到标准范围(通常是0到1或-1到+1)。
计算公式
对于要缩放到[0,1]范围的数据,使用以下公式:
\[x' = \frac{x - x_{min}}{x_{max} - x_{min}}\]
其中:
- x' 是标准化后的值
- x 是原始值
- x_min 是数据集中的最小值
- x_max 是数据集中的最大值
线性缩放在满足以下条件时是较好的选择:
数据特点
- 数据的上下限变化不大
- 离群值较少或没有
- 数据在范围内较均匀分布
实际应用示例 以年龄(age)特征为例,线性缩放是合适的标准化方法:
- 明确的取值范围(0到100)
- 极端值较少(仅0.3%超过100岁)
- 分布相对均匀
- 需要保留所有年龄段的代表性
局限性
- 对非线性分布的数据效果不佳
- 与Z分数标准化相比,处理偏态分布时效果较差
注意: 大多数实际特征都不会完全满足线性缩放的理想条件。对于非线性分布明显的特征,Z分数标准化通常是更好的选择。
Z分数标准化
Z分数标准化是一种常用的标准化方法,它基于数据的均值和标准差进行计算。
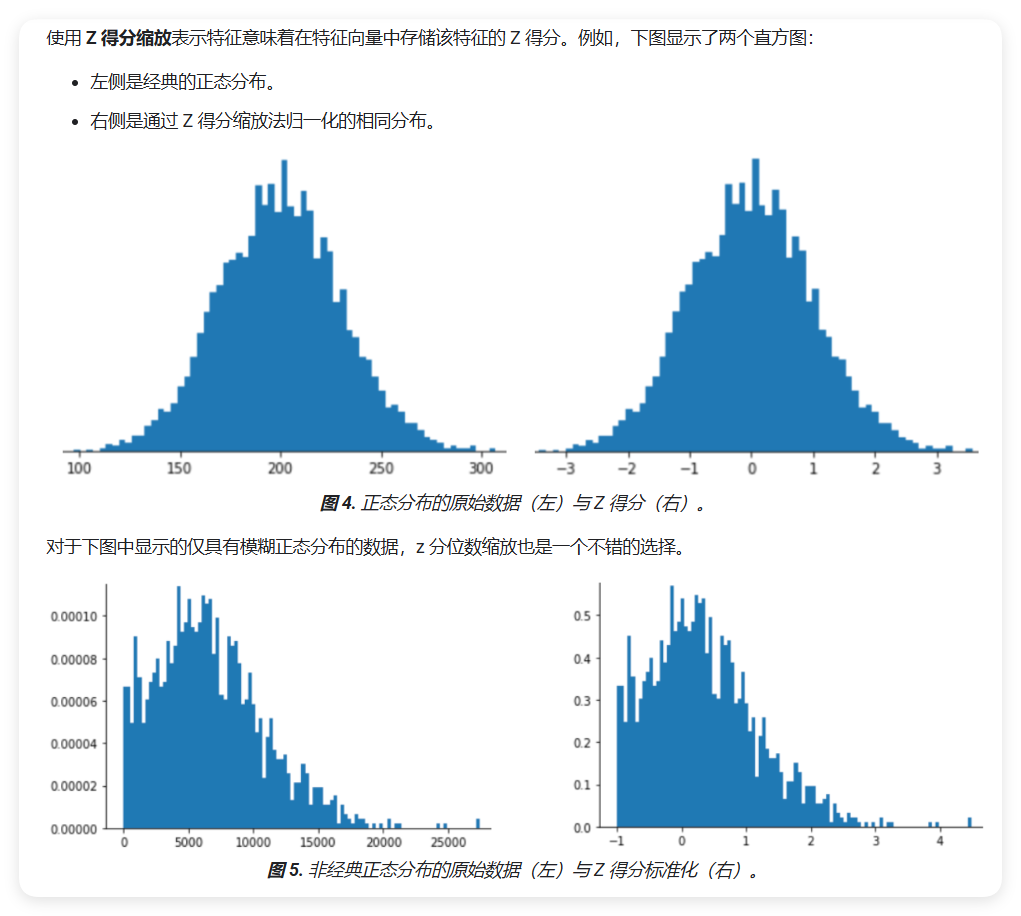
定义
Z分数表示某个值与平均值之间相差多少个标准差。例如:
- Z得分为+2.0表示该值比平均值高2个标准差
- Z得分为-1.5表示该值比平均值低1.5个标准差
数据转换
Z分数标准化会将数据转换为标准正态分布: - 原始数据可能呈现任意分布 - 标准化后的数据近似正态分布 - 转换后的数据均值为0,标准差为1
计算公式
对于数据点x,其Z分数计算如下:
\[z = \frac{x - \mu}{\sigma}\]
其中:
- z 是标准化后的Z分数
- x 是原始值
- μ 是数据集的均值
- σ 是数据集的标准差
注意: Z分数标准化特别适合处理近似正态分布的数据,或者需要将数据转换为正态分布的场景。
对数缩放
对数缩放是一种重要的数据转换技术。在理论上,对数可以使用任何底数;在实践中,通常使用自然对数(ln)。
基本公式
一般对数变换: \[x' = \log_b(x)\] 其中b是对数的底数。
自然对数变换(最常用): \[x' = \ln(x) = \log_e(x)\]
处理零值和小值时的变换: \[x' = \ln(x + 1)\]
处理负值的符号对数变换: \[x' = sign(x) \cdot \ln(|x| + 1)\]
其中sign(x)表示x的符号:
- 当x > 0时,sign(x) = 1
- 当x < 0时,sign(x) = -1
- 当x = 0时,sign(x) = 0
适用场景
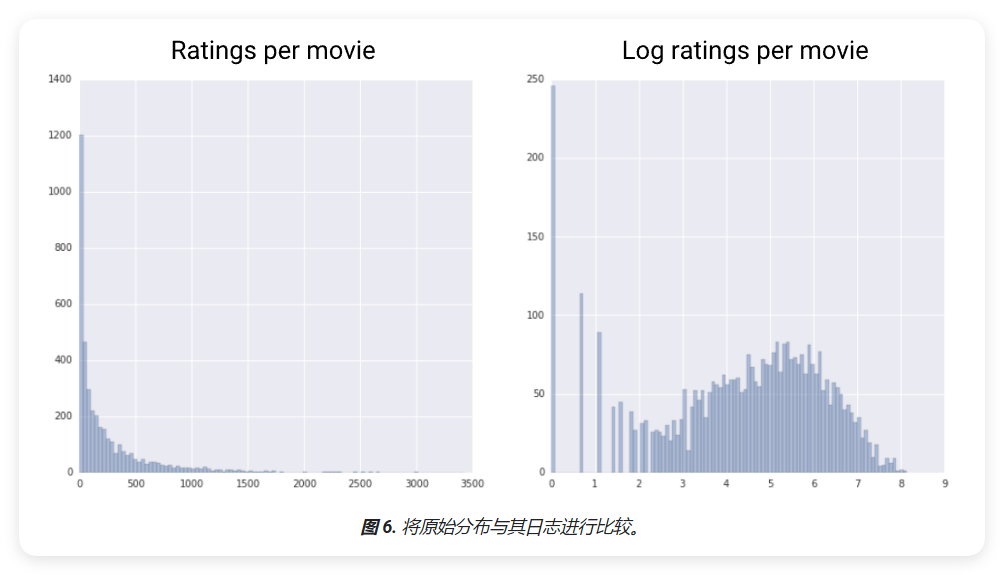
当数据符合幂律分布时,对数缩放会很有帮助。幂律分布通常具有以下特征:
- X 值较低时,Y 值非常高
- 随着 X 值的增加,Y 值会快速下降
- 当 X 值较高时,Y 值趋于较低水平
应用示例
电影评分是幂律分布的典型例子。在电影评分数据中:
- 少数电影获得了大量用户评分 (X 值较低,Y 值较高)
- 大多数电影的用户评分较少 (X 值较高,Y 值较低)
对这类数据进行对数缩放可以改变分布,有助于训练出能够做出更准确预测的模型。
剪裁技术
剪裁是一种处理异常值的重要技术。它通过设定上下限,将超出范围的值限制在指定范围内。
基本公式
基本剪裁: \[x' = \begin{cases} x_{min} & \text{if } x < x_{min} \\ x & \text{if } x_{min} \leq x \leq x_{max} \\ x_{max} & \text{if } x > x_{max} \end{cases}\]
百分位数剪裁: \[x' = \begin{cases} P_1 & \text{if } x < P_1 \\ x & \text{if } P_1 \leq x \leq P_{99} \\ P_{99} & \text{if } x > P_{99} \end{cases}\]
其中P₁和P₉₉分别表示第1和第99百分位数。
适用场景
剪裁技术在以下情况特别有用:
- 存在极端异常值
- 数据分布有长尾
- 模型对异常值敏感
- 需要保持大部分数据不变
应用示例
收入数据是使用剪裁的典型例子:
- 大多数人的收入在一个正常范围内
- 少数极高收入会显著影响数据分布
- 可以将高于99百分位的收入限制在P₉₉值
- 同样处理低于1百分位的异常低值
剪裁可以在保留数据总体特征的同时,减少极端值对模型训练的影响。
注意: 剪裁时需要谨慎选择阈值,过度剪裁可能会丢失重要信息。
数值数据:分箱
分箱(也称为分桶)是一种特征工程,将不同的数值子范围分组到分类数据中。在许多情况下,分箱会将数值数据转换为分类数据。例如,假设某个函数名为 ( x ),其最小值为 15;最高值为 425 值助分箱,您可以使用以下五个分箱:
- 分箱 1: 15 到 34
- 分箱 2: 35 到 117
- 分箱 3: 118 到 279
- 分箱 4: 280 到 392
- 分箱 5: 393 到 425
分箱 1 的范围为 15 到 34,因此 ( x ) 的每个介于 15 到 34 之间的值最终出现在分箱 1 中。在这些分箱上训练的模型不会有任何不同,更改为 ( x ) 值 17 和 29,因为这两个值都位于分箱 1 中。
特征向量与分箱
特征向量表示这五个分箱如下:
| 分箱号 | Range | 特征向量 |
|---|---|---|
| 1 | 15-34岁 | [1.0, 0.0, 0.0, 0.0, 0.0] |
| 2 | 35-117人 | [0.0, 1.0, 0.0, 0.0, 0.0] |
| 3 | 118-279人 | [0.0, 0.0, 1.0, 0.0, 0.0] |
| 4 | 280-392人 | [0.0, 0.0, 0.0, 1.0, 0.0] |
| 5 | 393-425人 | [0.0, 0.0, 0.0, 0.0, 1.0] |
即使 ( x ) 是数据集中的单列,分箱也会产生模型将 ( x ) 视为五个独立的特征。因此,模型学习单独的权重。
分箱是压缩的一个很好的替代方案或载体,满足以下条件:
- 特征与 label 弱或不存在。
- 对特征值进行聚类时。
分箱可能会让人感觉不合常理,因为上一个示例以相同方式处理值 37 和 115。但当然,对于某些特征,分箱比线性特征更有效。
分位数分箱
分箱可以建立分箱边界,或每个分箱中的样本数完全匹配或几乎相等。分位数分箱大部分情况下隐含离群值。
分位数分箱可以解决等间距区间的问题。分位数分箱将样本分成相等数量的组,而不是相等数量的存储区。
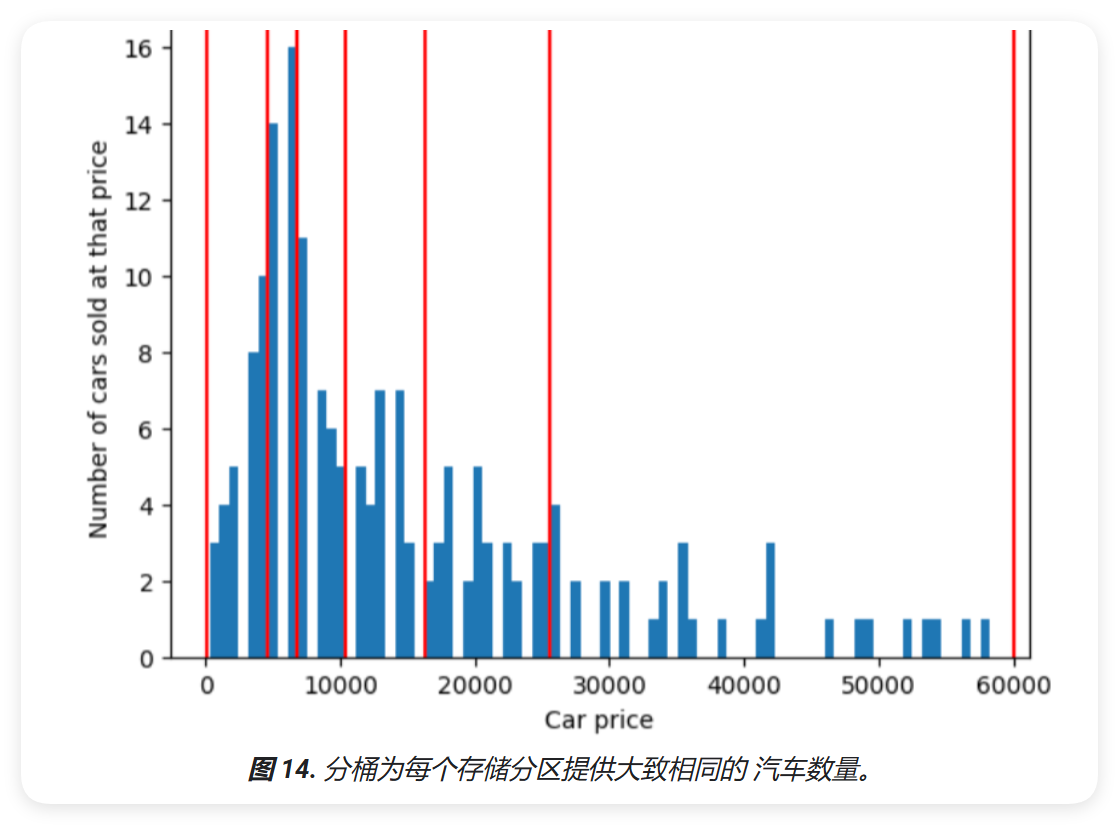
为了说明分位数分箱所解决的问题,请考虑下图所示的等间距区间,其中每个分区 10 个存储区中的 10 个表示正好 10,000 美元的跨度。请注意,范围从 0 到 10,000 包含数十个样本,但 50,000 到 60,000 的分箱只包含 5 个样本。因此,模型有足够的样本来使用 0 到 10,000 个,但对于 50,000 到 60,000 的存储分区,没有足够的样本进行训练。
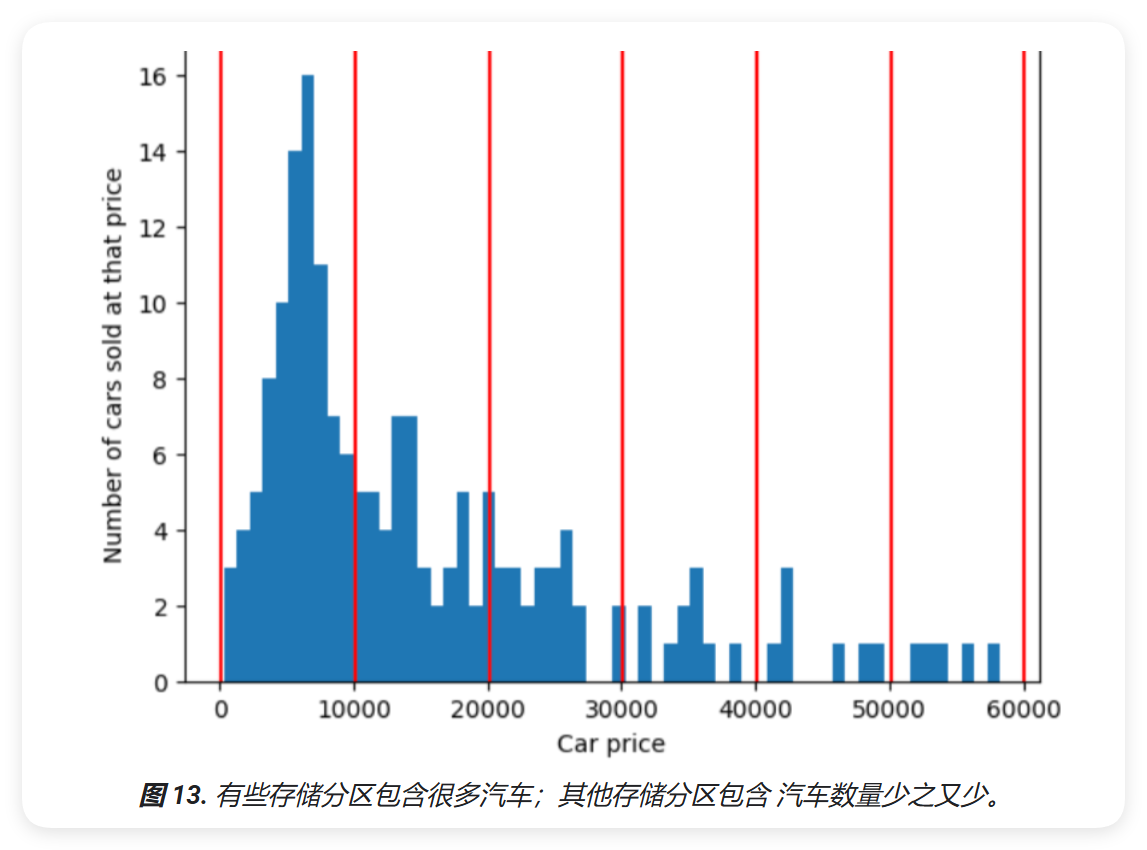
相比之下,下图则使用分位数分桶来划分汽车价格分箱,每个分桶中的样本数量大致相同。 请注意,有些分箱的价格范围较窄,而其他分箱的价格范围较窄 价格范围很广。
数值数据:清理
数据清理是数据预处理的重要步骤,旨在提高数据质量,确保模型训练的有效性。数据集中可能存在多种问题,例如:
| 问题类型 | 示例 |
|---|---|
| 省略的值 | 人口普查员未能记录居民的年龄。 |
| 重复示例 | 服务器会将相同的日志上传两次。 |
| 超出范围的特征值 | 有人不小心输入了额外的数字。 |
| 标签错误 | 一名人工评估员错误地将一张树的图片标记为枫树。 |
您可以编写程序或脚本来检查以下问题:
- 省略的值
- 重复示例
- 超出范围的特征值
标签生成与评估
如果标签由多人生成,我们建议您确保每个标注者是否生成了有效的标签集。某个评估者可能比其他评估者更严格,或使用一组不同的评分标准。
一旦检测到,通常需要“修正”包含不良特征的示例,从数据集中移除或输入调整标签或不良标签。
数值数据:良好数值特征的特性
每个特征都应具有清晰、合理且明显的意义。例如,以下特征的含义混淆:
不建议的命名
House_age: 851472000
建议的命名
house_age_years: 27
尽管本单元花费了大量时间离群值,主要是这一点非常重要。在某些情况下(而不是糖糊的工程选择)会导致不明确的值。例如,以下
user_age_in_years 来自未经检查的来源适当的值:
不建议
user_age_in_years: 224
但是,人们可能是 24 岁: #### 建议 -
user_age_in_years: 24
数值数据:多项式转换
有时,当机器学习从业务领域相关知识时,一个变量与另一个变量的平均,立方或其他相关变量,不妨创建一个合成特征以有数值特征的基础。
假设数据点分布如下,其中粉色圆圈表示一个类别(例如某种树)和绿色三角形表示其他类别(或树木的种类):
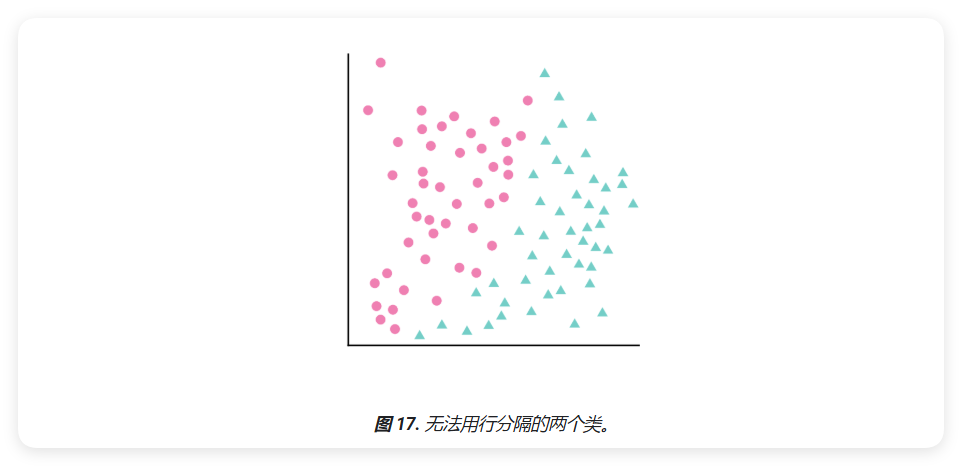
不可能绘制出将两个类别完全分隔的直线,但也可以绘制出这样的曲线:
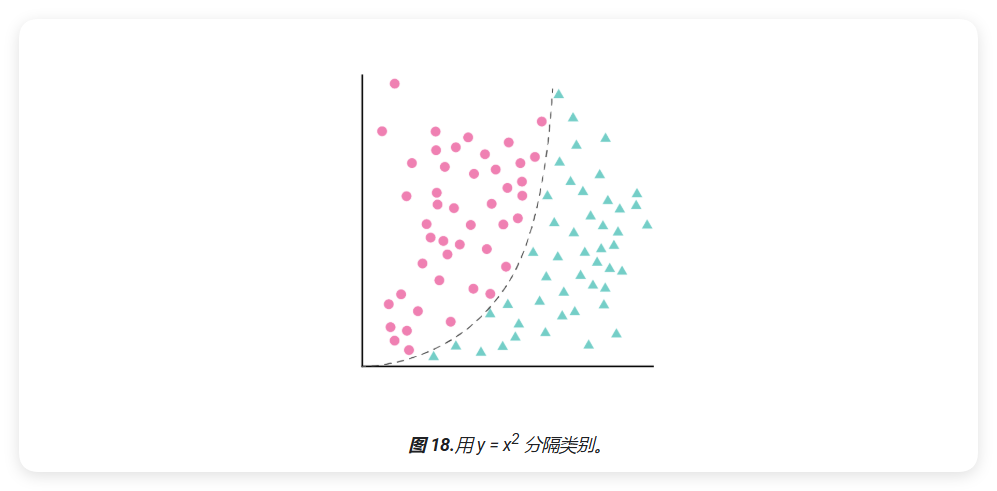
线性回归模型与多项式转换
线性回归模型可以描述为一个包含一项特征 ( x_1 ) 的线性模型:
\[ y = b + w_1 x_1 \]
其他功能可以通过添加条款 ( w_2 x_2 )、( w_3 x_3 ) 等来处理。
在这种情况下,可能会找到重要的权重 ( w_1, w_2, w_3 )(如果有其他功能),可最大限度地减少模型损失。但所示的数据点可能不能用线性分隔。
多项式转换
可以同时保持线性方程并允许非线性方法来定义一个新项 ( x_2 ),将其简称为 ( x_1 ) 平方:
\[ x_2 = x_1^2 \]
这将使特征转换为多项式形式,其他功能上一个线性公式变为:
\[ y = b + w_1 x_1 + w_2 x_2 \]
这被视为线性回归和多项式转换的结合,尽管包含隐蔽平滑功能,即多项式转换。不更改线性模型的训练方式。
通常,感知的数据特征会与其本身相关,即提到到一定程度。机器学习从业者可以做出明智的预测,适应当前的情况。
相应地,分类数据与特征组合,经历常常会有不同的特征。
以上是数值数据处理的基础概念,后续的内容请看下一篇博客。