机器学习入门01
本科毕设的研究方向与隐私计算有关,联邦学习算是其中的一个分支技术,机器学习算是其中的一个基础理论。因此打算记录一下机器学习的一些基础知识。
参考教程
以下是我计划学习的机器学习课程资源:
Google机器学习速成课程 - Google官方入门教程,内容简洁实用
吴恩达机器学习课程 - Coursera上最受欢迎的机器学习课程之一,适合入门
李宏毅机器学习课程 - 台湾大学教授的机器学习课程,讲解深入浅出
李沐动手学深度学习 - 亚马逊资深科学家的实战课程,注重代码实践
今天先从google的机器学习速成课程开始。
什么是机器学习(Machine Learning)?
从基本层面来说,机器学习是指训练一款名为模型(Model)的软件,以便做出有用的预测或根据数据生成内容。
机器学习系统类型
根据机器学习系统学习预测或生成内容的方式,它们可分为以下一个或多个类别:
- 监督式学习(Supervised Learning)
- 非监督式学习(Unsupervised Learning)
- 强化学习(Reinforcement Learning)
- 生成式 AI(Generative AI)
监督式学习(Supervised Learning)
监督式学习模型在看到包含正确答案的大量数据后,可以发现产生正确答案的数据元素之间的关联,然后进行预测。这就像学生通过研究包含问题和答案的旧考试来学习新材料。学生在使用足够多的旧版考试进行训练后,就可以做好准备参加新版考试了。这些机器学习系统是"监督式"的,这意味着人类会向机器学习系统提供包含已知正确结果的数据。
监督式学习的两种最常见用例是回归(Regression)和分类(Classification)。
回归(Regression)
回归模型可以预测连续的数值(Continuous Value)。回归模型的输出是一个具体的数字,比如预测房价是500万元,或预测明天的降雨量是50毫米。
以下是一些典型的回归应用场景:
| 场景 | 输入数据 | 预测结果 |
|---|---|---|
| 房价预测 | 建筑面积、位置、装修等级、周边配套等 | 房屋价格(元) |
| 行程时间预测 | 路况、天气、历史数据等 | 到达时间(分钟) |
分类(Classification)
分类模型用于预测某个对象属于特定类别的可能性。与输出连续数值的回归模型不同,分类模型输出的是离散的类别(Discrete Category)标签(Category Label)。
分类模型可以分为:
- 二元分类(Binary Classification):输出仅包含两个类别,如判断邮件是否为垃圾邮件(是/否)
- 多类分类(Multi-class Classification):可以输出多个类别,如识别图片中的天气类型(晴天/雨天/雪天等)
分类的典型应用包括:
- 垃圾邮件检测
- 图像识别
- 疾病诊断
- 信用评估
非监督式学习(Unsupervised Learning)
非监督式学习模型通过获得不含任何正确答案的数据来进行预测。非监督式学习模型的目标是找出数据中具有意义的模式。换句话说,模型没有关于如何对每项数据进行分类的提示,而是必须推断自己的规则。
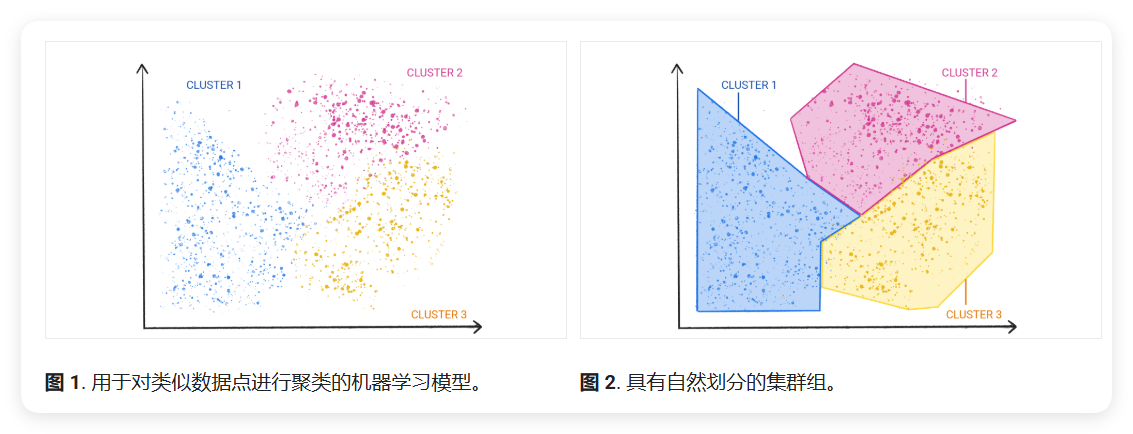
一种常用的非监督式学习模型采用了一种称为聚类(Clustering)的技术。该模型会找到用于划分自然分组的数据点。
强化学习(Reinforcement Learning)
强化学习(Reinforcement Learning)模型根据在环境中执行的操作获得奖励或惩罚,从而进行预测。强化学习系统会生成政策,定义用于获得最多奖励的最佳策略。
强化学习用于训练机器人执行任务(例如在房间内四处走动),以及训练 AlphaGo 等软件程序玩围棋。
生成式 AI(Generative AI)
生成式 AI 是一类根据用户输入生成内容的模型。例如,生成式 AI 可以创作独特的图片、音乐作品和笑话;它可以总结文章、说明如何执行任务或编辑照片。
生成式 AI 可以接受各种输入,并创建各种输出,例如文本、图片、音频和视频。它还可以接受和创建这些值的组合。例如,模型可以接受图片作为输入,并创建图片和文本作为输出,也可以接受图片和文本作为输入,并创建视频作为输出。
我们可以通过生成模型的输入和输出来讨论它们,通常以"输入类型"到"输出类型"的形式写出。例如,以下是生成式模型的部分输入和输出列表:
- 文本到文本
- 文本到图像
- 文本到视频
- 文本转代码
- 文本转语音
- 图片和文本到图片
生成式 AI 如何运作?概括来讲,生成式模型会学习数据中的模式,目标是生成新的但类似的数据。 为了生成独特且富有创意的输出,生成式模型最初使用非监督式方法进行训练,在这种方法中,模型会学习模仿其训练数据。有时,系统会使用监督学习或强化学习对与模型可能被要求执行的任务(例如总结文章或编辑照片)相关的特定数据进行进一步训练。
监督式学习基础概念
监督式学习的任务定义明确,可用于多种场景,例如识别垃圾内容或预测降水。
监督式机器学习基于以下核心概念:
- 数据(Data)
- 模型(Model)
- 训练(Training)
- 评估(Evaluation)
- 推理(Inference)
数据(Data)
数据是机器学习的驱动力。数据的形式为存储在表中的单词和数字,或以图片和音频文件中捕获的像素和波形值的形式。我们将相关数据存储在数据集(Dataset)中。
例如,我们可能拥有以下类型的数据集:
- 猫的图片集
- 房价数据
- 天气信息
数据集由包含特征(Feature)和标签(Label)的各个样本(Sample)组成。您可以将样本视为电子表格中的一行。其中:
- 特征是监督式模型用于预测标签的值
- 标签就是"答案",也就是我们想要模型预测的值
以预测降雨的天气模型为例:
| 类型 | 内容 |
|---|---|
| 特征 | 纬度、经度、温度、湿度、云覆盖范围、风向、气压 |
| 标签 | 降雨量 |
同时包含特征和标签的样本称为有标签样本(Labeled Sample)。
数据集特征(Dataset Characteristics)
数据集的特征是规模(Scale)和多样性(Diversity)。大小表示样本数量。多样性表示这些样本所涵盖的范围。好的数据集要既大又多样化。
有些数据集规模庞大且丰富多样。然而,有些数据集很大但多样性较低,还有一些虽然较小但多样性较高。换言之,大型数据集不能保证足够的多样性,高度多样性的数据集也无法保证有足够的样本。
例如:
- 数据集可能包含 100 年的数据,但只包含 7 月份的数据。使用此数据集来预测 1 月的降雨量会产生较差的预测。
- 相反,数据集可能仅涵盖几年,但包含每月。此数据集可能产生较差的预测,因为它未涵盖足够的年份解释可变性。
数据集的特征数量也可以作为特征。例如:
- 某些天气数据集可能包含数百个特征,从卫星图像到云覆盖率值,不一而足
- 其他数据集可能只包含三四个特征,例如湿度、大气压力和温度
具有更多特征的数据集有助于模型发现其他模式并做出更好的预测。但是,特征较多的数据集并不一定生成的模型能够提供更好的预测,因为某些特征可能与标签没有因果关系。
模型(Model)
在监督式学习中,模型是复杂的数字集合,用于定义从特定输入特征模式与特定输出标签值的数学关系。模型通过训练发现这些模式。
训练(Training)
监督式模型必须先接受训练,然后才能进行预测。为了训练模型,我们为模型提供一个带有标签样本的数据集。
训练过程包括以下步骤:
- 模型的目标是找到根据特征预测标签的最佳解决方案
- 模型通过将预测值与标签的实际值进行比较来找到最佳解决方案
- 根据预测值与实际值(定义为损失(Loss))之间的差异,模型会逐步更新其解决方案
- 模型会学习特征与标签之间的数学关系,以便对未见过的数据做出最佳预测
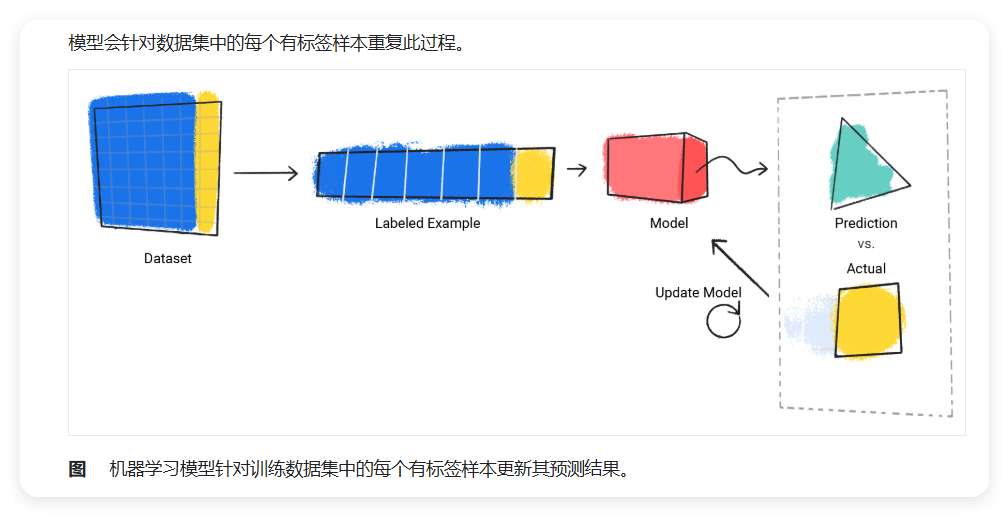
例如,如果模型预测降雨量为 1.15 inches,但实际值为 0.75 inches,则模型会修改其解决方案,使其预测更接近 0.75 inches。在模型查看数据集中的每个样本(在某些情况下,多次查看)后,会得到一个能够为每个样本做出平均最佳预测的解决方案。
通过这种方式,模型可以逐步学习特征与标签之间的正确关系。这种逐渐理解的机制也是为什么庞大、多样化的数据集能够产生更好的模型的原因。该模型看到了更多值范围更广的数据,并且改进了对特征与标签之间关系的理解。
在训练期间,机器学习从业者可以对模型用于进行预测的配置和功能进行细微调整。例如,某些特征的预测能力高于其他特征。因此,机器学习从业者可以选择模型在训练期间使用哪些特征。例如,假设天气数据集包含 time_of_day 作为特征。在这种情况下,机器学习从业者可以在训练期间添加或移除 time_of_day,以查看在使用或不使用该模型的情况下,模型是否能够更好地进行预测。
评估(Evaluation)
我们会评估经过训练的模型,以确定它的学习效果。在评估模型时,我们会使用加标签的数据集,但仅向模型提供数据集的特征。然后,我们会将模型的预测结果与标签的真实值进行比较。
评估模型时,我们通常会使用以下指标:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
根据模型的预测,我们可能会在实际应用中部署模型之前进行更多的训练和评估。
推理(Inference)
对评估模型的结果感到满意后,我们就可以使用模型对无标签样本进行预测(称为推断)。在天气应用示例中,我们将为模型提供当前的天气条件(如温度、大气压和相对湿度),并预测降雨量。
以上是机器学习的基础概念,后续的内容请看下一篇博客。