了解Diffusion Language Model
我们熟悉的 Transformer 等模型采用“自回归”方式逐词生成文本,这限制了生成速度且不易保证长文本连贯。受图像生成领域成功的 扩散模型 (Diffusion Model) 启发,研究者将其引入文本生成,扩散语言模型 (Diffusion Language Model) 应运而生。
什么是扩散模型?
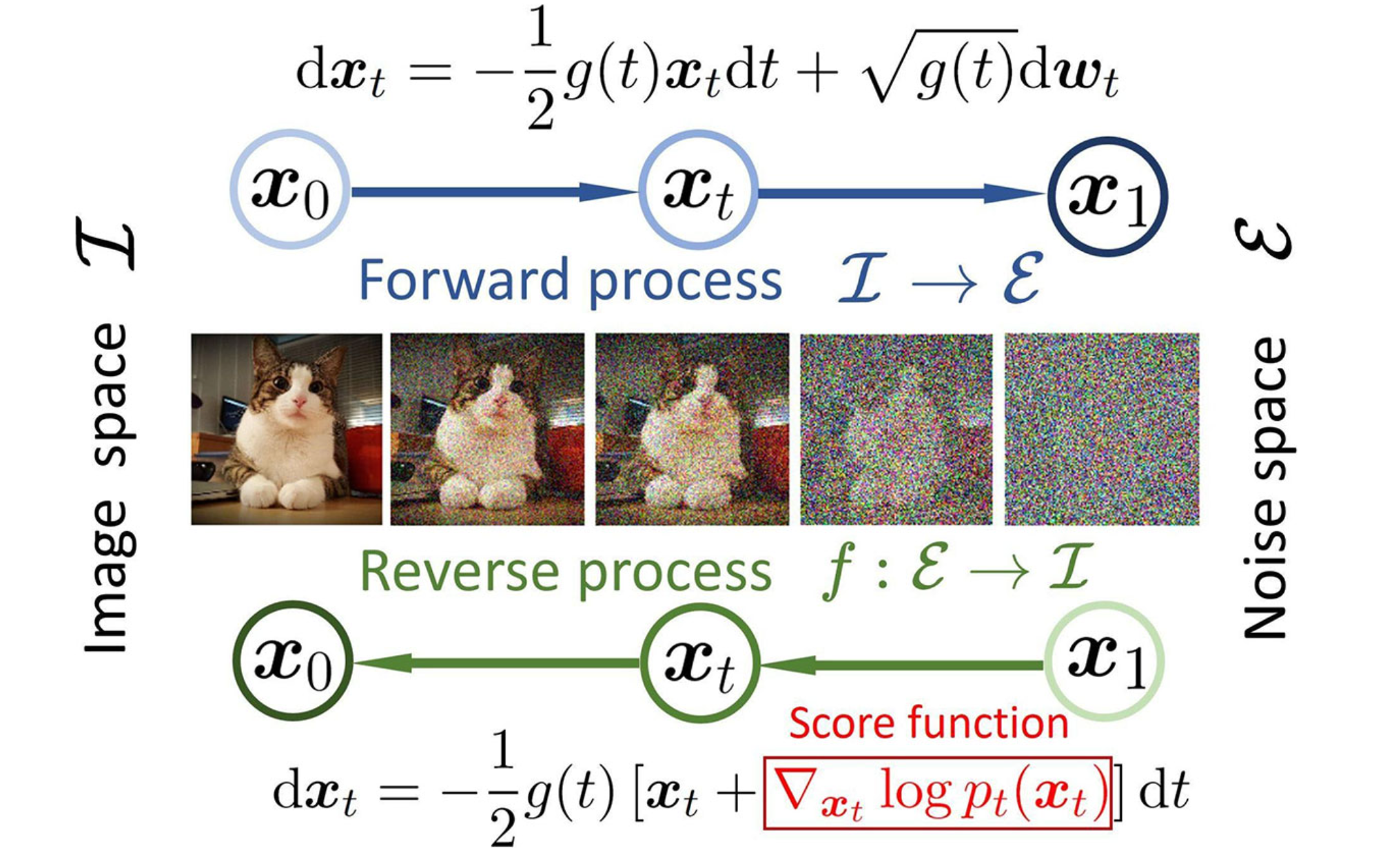
在深入了解其如何应用于语言之前,我们先通过一个直观的例子——图像生成——来理解扩散模型的核心思想。它主要包含两个过程:
前向过程(Forward Process):也叫“扩散”过程。想象一下,我们从一张清晰的图片开始,一步步地、逐渐地向图片中添加微小的“噪声”,直到这张图片完全变成一个毫无规律的噪声图。这个过程是固定的、可控的。
反向过程(Reverse Process):也叫“去噪”过程。这是真正的“生成”环节。我们训练一个神经网络,让它学会上述过程的“逆操作”——即从一张纯噪声的图片开始,一步步地、逐渐地去除噪声,最终还原出一张清晰、有意义的图片。
一旦模型学会了如何“去噪”,我们就可以给它任何随机噪声,让它“创造”出全新的、从未见过的图片。
如何将扩散模型用于文本?
直接将扩散模型应用于文本面临一个核心挑战:文本是离散的,而扩散过程处理的是连续的数据。我们无法像给图片像素值加噪声那样,给一个“词”加上一点“噪声”变成另一个“半词”。
解决方案是:在连续空间中操作。
我们不直接处理文字,而是先将文字通过 词嵌入(Word Embedding) 技术转换为高维度的连续向量。这样,文本序列就变成了一组向量,我们可以在这个连续的向量空间中执行扩散和去噪过程。
Diffusion 语言模型的工作原理
理解了以上概念后,扩散语言模型的工作流程就清晰了:
- 前向过程:取一个句子,将其转换为词向量序列。然后,逐步向这些向量中添加噪声,直到它们变成一组随机向量。
- 反向过程:训练一个模型(通常是基于 Transformer 架构)来学习逆转这个过程。模型的任务是接收一串加了噪声的向量,并预测出“更干净”的向量应该是什么样子。
- 文本生成:当需要生成新文本时,我们从一组完全随机的向量开始,然后反复利用训练好的去噪模型进行迭代处理。每一步,向量都会变得“更清晰”一点,逐渐从无序的噪声收敛为有意义的词向量。最后,将这些“去噪”完成的词向量转换回人类可读的文字,就完成了一次文本生成。
Diffusion 语言模型的优势
与传统的自回归模型相比,扩散语言模型展现出一些独特的优势:
- 并行生成:扩散模型在生成时是迭代式地对整个序列进行优化的,而不是像自回归模型那样必须逐词生成。这为并行计算和更快的生成速度提供了可能。
- 全局一致性:由于模型的每一步去噪都是基于对整个序列的观察,它能更好地捕捉全局依赖关系,生成的文本在长距离连贯性和结构完整性上可能更具优势。
- 可控性更强:扩散模型的迭代特性使其在生成过程中更容易被引导和控制。我们可以通过修改去噪过程来控制生成文本的风格、主题或结构,使其更适用于文本编辑、修复和改写等任务。
前沿研究进展
尽管扩散语言模型是一个较新的研究方向,但它已经展现出惊人的潜力,涌现了许多前沿工作:
- 大规模模型的成功:以 LLaDA 为代表的研究表明,当参数规模扩大到数十亿级别时,精心设计的扩散语言模型在性能上足以媲美甚至在某些复杂任务上超越顶尖的自回归模型(如 LLaMA3、GPT-4o),这证明了该技术路线的可行性与潜力。
- 效率与质量的权衡:一些研究也指出,当前扩散语言模型在推理时为了达到高质量的生成效果,可能需要较多的“去噪”迭代步骤,这导致其计算成本相对较高。如何平衡生成质量与推理效率,是目前该领域的研究热点之一。
- 多模态统一框架:部分工作(如 Transfusion 架构)尝试将扩散模型与 Transformer 深度融合,在一个统一的框架内同时处理文本和图像的生成任务,为多模态内容创作提供了新的思路。
- 行业巨头的投入:以 Google 推出的 Gemini Diffusion 为例,科技巨头们也开始在该领域发力,进一步验证了文本扩散模型作为下一代生成技术核心的潜力。
总结
扩散语言模型通过借鉴图像生成领域的成功经验,为自然语言生成任务提供了一种全新的、非自回归的解决方案。它通过在连续的词向量空间中进行“加噪”和“去噪”,克服了文本数据的离散性难题。尽管这一领域仍处于快速发展阶段,但其在并行生成、全局连贯性和可控性方面展现出的巨大潜力,预示着它将成为未来自然语言处理领域一个重要的研究方向。