了解Transformer
在之前的文章中我们了解到,RNN(及其变体如 LSTM、GRU)在处理序列数据时,必须按照时间步顺序计算,这导致其无法进行大规模并行计算。同时,它也难以解决长距离依赖的问题。
为了解决这两个核心痛点,一种全新的、不依赖于循环结构的模型——Transformer 横空出世。
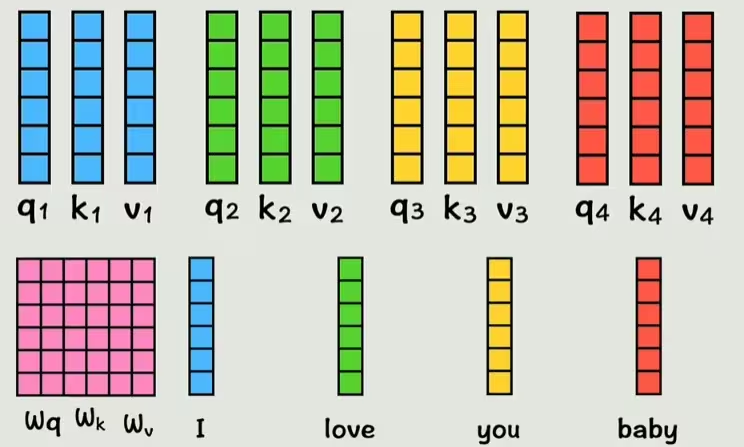
和之前一样,输入神经网络的数据,要先转换为 词嵌入(Word Embedding) 向量。
第一步:融入位置信息
由于 Transformer 抛弃了 RNN 的循环结构,模型本身无法感知输入序列中词语的先后顺序。
为了解决这个问题,我们需要给每个词的词向量中添加 位置编码(Positional Encoding),以此来表示这个词在句子中的绝对或相对位置。
这样,每个词的输入向量就同时包含了语义信息和位置信息。
核心机制:自注意力(Self-Attention)
仅仅包含位置信息是不够的,每个词的向量中还不包含与其他词的关系。为了让模型“注意”到句子中其他词的存在并建立联系,Transformer 引入了 自注意力机制。
该机制的核心思想是为句子中的每个词动态地计算一个权重系数,这个权重代表了在编码当前词时,句子中其他词对它的重要性。这是通过三个特殊的向量来实现的:
- Query (查询向量 Q):代表当前词,用于去“查询”其他词。
- Key (键向量 K):代表被查询的词,用于和查询向量进行匹配。
- Value (值向量 V):代表被查询词的实际内容。
这三个向量是通过将每个词的词向量(已包含位置编码)分别与三个可训练的权重矩阵 Wq、Wk、Wv 相乘得到的。
计算过程如下: 1. 拿一个词的查询向量 q 去和所有词(包括它自己)的键向量 k 做点积,得到一个 注意力分数。这个分数衡量了两个词之间的相关性。 2. 对得到的分数进行归一化处理(例如通过 SoftMax)。 3. 将归一化后的分数与每个词对应的值向量 v 相乘。 4. 将所有加权后的值向量 v 相加,就得到了一个新的向量 a。
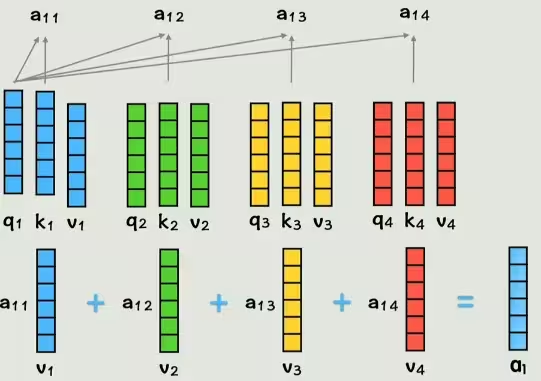
这个新向量 a 就包含了整个句子上下文的信息,并且是为当前词量身定制的。对句子中的每一个词都执行相同的操作,我们就能得到一组全新的、富含上下文信息的词向量。
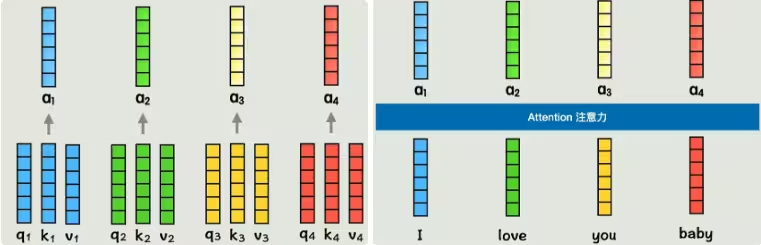
优化:多头注意力(Multi-Head Attention)
一个词与另一个词的关系可能有很多种(例如,语法关系、语义关系等)。如果只用一组 Wq, Wk, Wv 矩阵来计算相关性,灵活性会很低。
因此,Transformer 提出了 多头注意力机制。它通过设置多组独立的 Wq, Wk, Wv 矩阵(每一组被称为一个“头”),将原始的 Q, K, V 映射到不同的子空间中,学习不同方面的相关性。
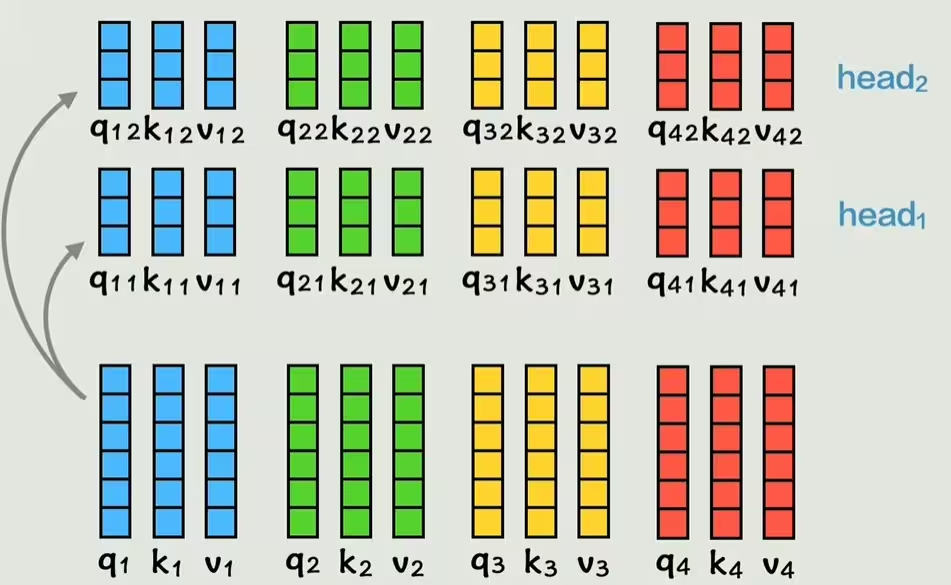
每个头都会独立地执行一次注意力计算,得到一个输出向量。最后,将所有头的输出向量拼接起来,再经过一次线性变换,就得到了最终的输出。这样,模型就能在不同维度上综合地理解词与词之间的关系。
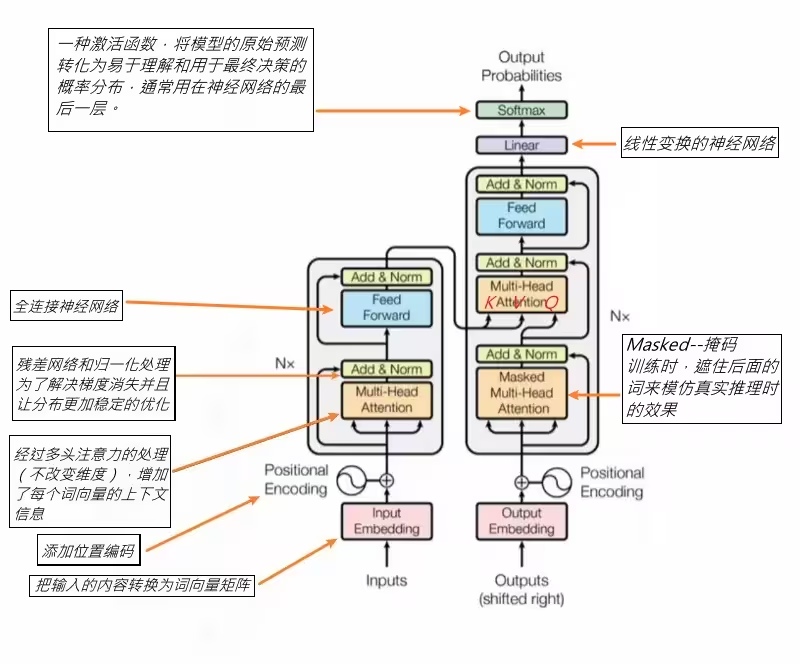
整体架构:编码器与解码器
Transformer 的整体架构由 编码器(Encoder) 和 解码器(Decoder) 两大部分组成,每一部分都由多层堆叠而成。我们上面介绍的多头注意力机制就是其核心组件。
- 编码器:负责将输入序列处理成一系列富含上下文信息的表示。
- 解码器:根据编码器的输出和之前已生成的结果,来生成下一个词。
总结
Transformer 通过引入自注意力机制和位置编码,完全摒弃了传统的循环和卷积结构。其强大的并行计算能力和捕捉长距离依赖的优势,使其在自然语言处理领域取得了革命性的成功,并为后续的 BERT、GPT 等大规模预训练模型奠定了基础。
参考自 B站up主 飞天闪客