机器学习入门09
今天继续进行机器学习的入门,主题是神经网络。
神经网络 (Neural Networks)
神经网络简介
神经网络是一种机器学习模型,灵感来源于生物神经网络。神经网络由多个神经元组成,每个神经元接收输入并生成输出。神经网络可以用于分类、回归和聚类等任务。
神经网络的组成部分
现在,我们的模型包含人们通常在提及神经网络时所指的所有标准组件:
- 一组节点,类似于神经元,并且位于层中。
- 一组权重,表示每个神经网络层与其下方的层之间的关系。下方的层可能是另一个神经网络层,也可能是其他类型的层。
- 一组偏差,每个节点一个偏差。
- 一个激活函数,对层中每个节点的输出进行转换。不同的层可能用有不同的激活函数。
⚠️ 警告:神经网络不一定总比特征组合好,但神经网络确实可以提供一种灵活的替代方案,在许多情况下效果都很好。
向网络添加层
在神经网络中,我们可以在输入层和输出层之间添加一个或多个中间层,这些中间层被称为隐藏层,其中的节点被称为神经元。
隐藏层中的每个神经元都会进行类似线性模型的计算:首先计算来自上一层所有输入的加权和,然后加上一个偏差值。这些神经元的输出值会作为下一层(输出层)神经元的输入,继续进行类似的计算过程。
所有计算过程都是线性的,该模型无法学习非线性关系。
激活函数(Activation Function)
激活函数是神经网络中的一种函数,用于将神经元的输出值转换为非线性关系。激活函数通常使用非线性函数,如ReLU、Sigmoid或tanh。
常用激活函数
常用作激活函数的三个数学函数是 Sigmoid 函数、tanh 函数和 ReLU 函数。
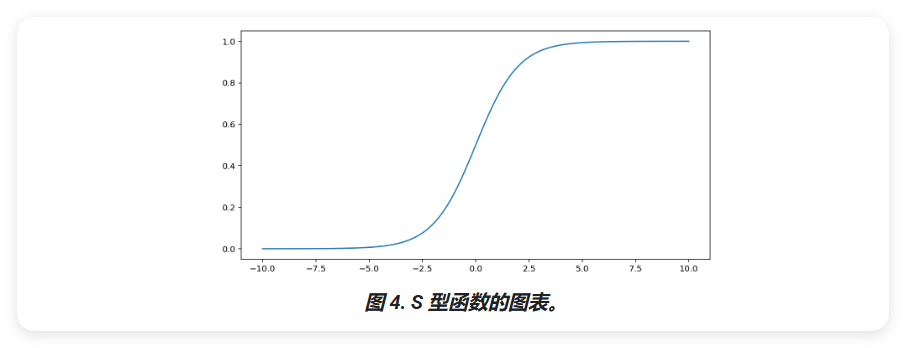
Sigmoid 函数
S 型函数(如上文所述)对输入 x 执行以下转换,从而生成一个介于 0 到 1 之间的输出值:
\[F(x) = \frac{1}{1+e^{-x}}\]
sigmoid 一词通常广泛用于指代任何 S 形函数。从技术层面来看,对特定函数 (F(x) = ) 来说,更准确的术语是逻辑函数。
下面是该函数的图表:
tanh 函数
tanh (简称"双曲正切")函数会转换输入 x,以生成介于 -1 和 1 之间的输出值:
\[F(x) = tanh(x)\]
以下是此函数的图表:
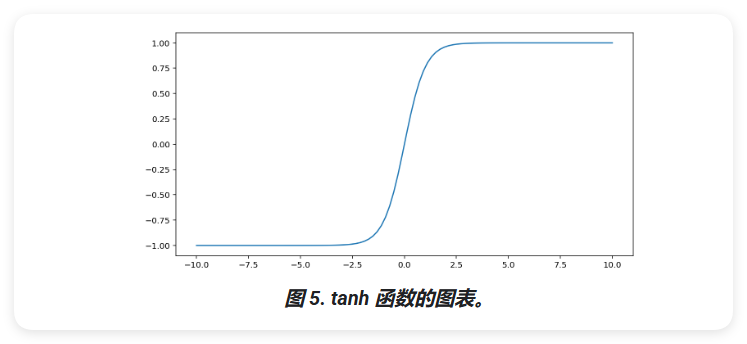
请注意,S 型函数的范围为 0 到 1,tanh 函数的范围为 -1 到 1。
ReLU 函数
修正线性单元激活函数(简称 ReLU)使用以下算法转换输出:
- 如果输入值 x 小于 0,则返回 0。
- 如果输入值 x 大于或等于 0,则返回输入值。
可以使用 max() 函数以数学方式表示 ReLU:
\[F(x) = max(0,x)\]
下面是该函数的图表:
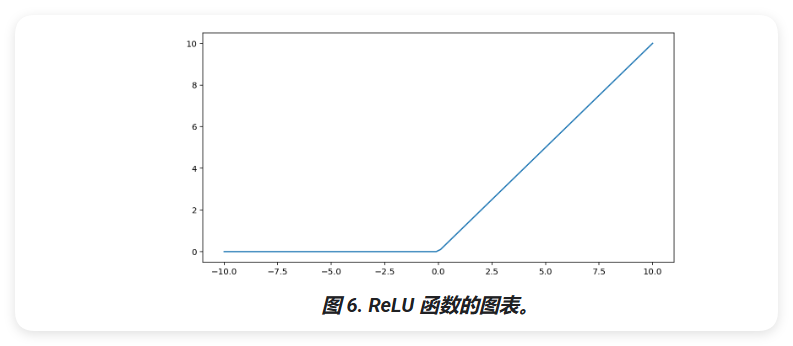
ReLU 作为激活函数的效果通常优于 S 型函数或 tanh 等平滑函数,因为它在神经网络训练期间不容易受到梯度消失问题的影响。与这些函数相比,ReLU 的计算也更容易。
反向传播算法(Backpropagation Algorithm)
反向传播算法是一种用于训练神经网络的算法。它通过计算损失函数对每个权重的梯度来更新权重,从而使模型能够更好地拟合训练数据。
反向传播算法的基本步骤如下:
前向传播:计算每个神经元的输出值。
计算损失函数:计算每个神经元的损失函数。
反向传播:计算每个权重的梯度。
更新权重:使用梯度更新权重。
梯度消失
较低神经网络层(更接近输入层)的梯度可能会变得很小。在深度网络(包含多个隐藏层的网络)中,计算这些梯度可能涉及对许多小项进行乘法。
当较低层的梯度值接近 0 时,梯度会被称为"消失"。具有消失梯度的层训练速度非常慢,或者根本无法训练。
ReLU 激活函数有助于防止梯度消失。
梯度爆炸
如果网络中的权重非常大,则较低层的梯度涉及许多大项的乘积。在这种情况下,可能会出现梯度爆炸:梯度太大而无法收敛。
批处理归一化有助于防止梯度爆炸,降低学习率也有助于防止梯度爆炸。
死 ReLU 单元
一旦 ReLU 单元的加权和低于 0,ReLU 单元可能会卡住。它会输出 0,对网络的输出没有任何贡献,并且在反向传播期间梯度无法再流经它。由于梯度源被切断,ReLU 的输入可能永远不会发生足够的变化,无法使加权和重新高于 0。
降低学习率有助于防止 ReLU 单元死亡。
此外,还有许多 ReLU 变体旨在解决此特定问题,例如 LeakyReLU,可以考虑将其用作激活函数来防止 ReLU 单元死亡。
Dropout 正则化
还有一种正则化形式,称为Dropout 正则化,对神经网络很有用。其工作原理是,在一个梯度步长中随机"丢弃"网络中的单元激活。丢弃的样本越多,正则化效果就越强:
- 0.0 = 不进行 dropout 正则化。
- 1.0 = 舍弃所有节点,模型学不到任何规律。
- 0.0 和 1.0 之间的值更有用。
神经网络:多类别分类
之前遇到de二元分类,可以从两个可能的选项中选择其一,例如:
- 指定电子邮件是垃圾邮件还是非垃圾邮件。
- 特定肿瘤是恶性或良性的。
在本节中,我们将介绍多类别分类模型,并从多种可能性中进行选择,例如:
- 这只狗是小猎犬、巴吉度猎犬还是寻血猎犬?
- 这朵花是西伯利亚鸢尾、荷兰鸢尾、蓝旗鸢尾吗?还是珍明须鸢尾?
- 那架飞机是波音 747、空客 320、波音 777 还是 Embraer 190?
- 这是一张苹果、熊、糖果、狗还是鸡蛋的图片?
现实世界中的一些多类别问题需要从数百万个类别中进行选择。以多类别分类为例,该模型可识别几乎任何事物的图像。
本部分详细介绍了多类别分类的两个主要变体:
- 一对多
- one-vs-one,通常称为 softmax
一对多
一对多提供了一种使用二元分类的方法来跨多个可能的标签进行一系列是或否预测。
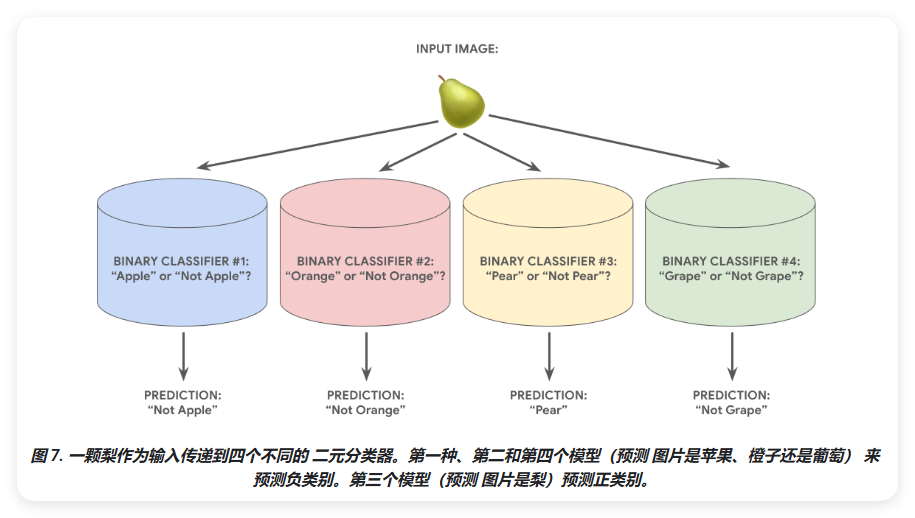
假设某个分类问题有 N 种可能的解决方案。一对多包含 N 个独立的二元分类器 - 每个二元分类器采用测每个可能的结果。在训练期间,模型会运行一系列二元分类器,对每个分类器进行训练,分类问题。
例如,假设有一张水果的图片,可能会训练不同的识别器,每个识别器都会回答不同的是或否问题:
- 这是一张苹果的图片吗?
- 这是一张橙子的图片吗?
- 这是一张香蕉的图片吗?
- 这是一张葡萄的图片吗?
下图说明了在实践中的运作方式。
当类别的总数较小时,这种做法相当合理,但随着类别的增多,其效率会逐渐降低。
我们可以使用一个深度神经网络来创建一个显著更高效的 one-vs.-all 模型,其中每个输出节点代表不同的类别。以下图片说明了这种方法。
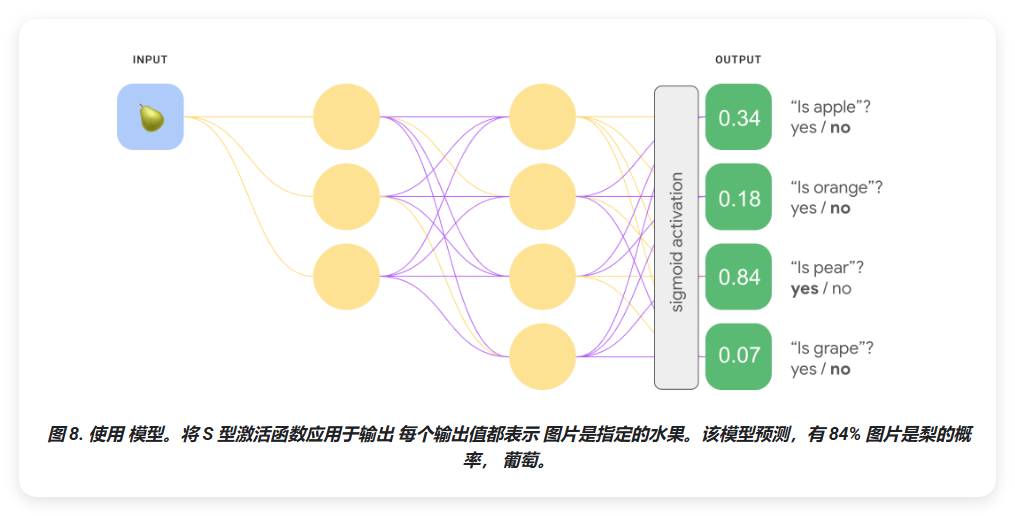
one-vs-one(softmax)
图 8 的输出层中的概率值之和并不等于 1.0(或 100%)。实际上,它们之和为 1.43。在一对一的方法中,每种二元结果集的概率是独立于其他所有结果集来确定的。也就是说,我们在确定"苹果"与"非苹果"的概率时,并没有考虑其他水果选项:"橙子"、"梨"或"葡萄"的可能性。
但如果我们想要预测每种水果相对于其他水果的概率会怎样呢?在这种情况下,我们不是预测"苹果" versus "非苹果",而是预测"苹果" versus "橙子" versus "梨" versus "葡萄"。这种多类分类称为 one-vs-one 分类。
我们可以使用与 one-vs-all 分类相同的神经网络架构实现 one-vs-one 分类,但需要进行一个关键改变。我们需要对输出层应用不同的转换。
对于一对一的情况,我们独立地将 sigmoid 激活函数应用于每个输出节点,这导致每个节点的输出值在 0 和 1 之间,但不能保证这些值相加恰好为 1。
对于 one-vs-one 的情况,我们可以应用一个称为 softmax 的函数,该函数在多类问题中为每个类别分配十进制概率,使得所有概率之和为 1.0。这种额外的约束有助于训练更快地收敛,否则收敛速度会更慢。
以下图像将我们的单对所有多类分类任务重新实现为单对单任务。请注意,为了执行 softmax,输出层前一层(称为 softmax 层)的节点数必须与输出层的节点数相同。
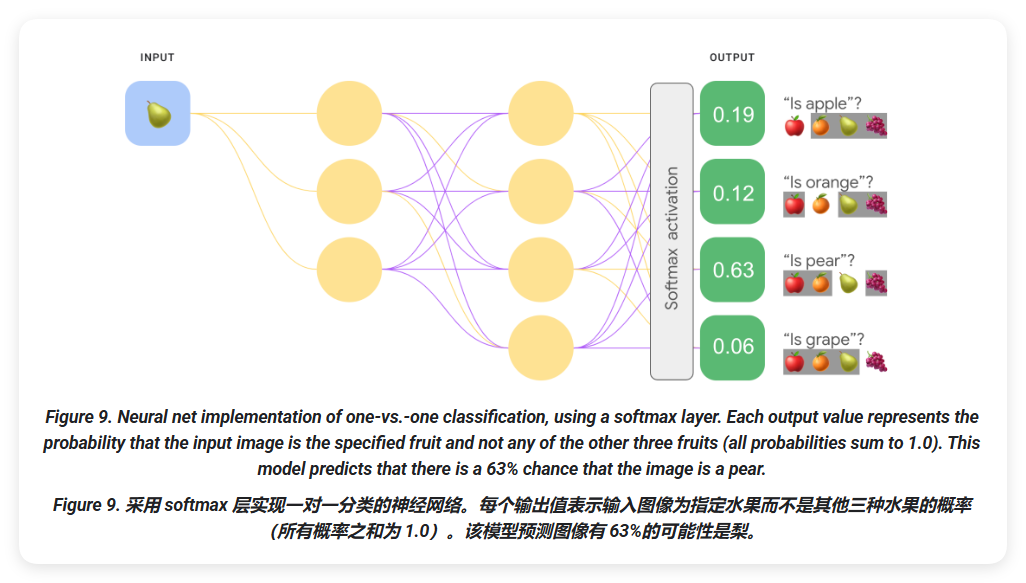
Softmax 选项
请考虑以下 softmax 变体:
完整 softmax 是我们一直以来讨论的 softmax,即 softmax 会计算每个可能类别的概率。
候选采样是指 softmax 计算概率的一个简化版本,只对样本和负标签进行采样。例如,如果我们想要确定一张输入图片是小猎犬还是寻血猎犬,我们不必为每个非狗的样本提供概率。
当类别数很小时,完整 softmax 的开销很小。但随着类别数量的增加,费用会变得非常高。候选采样可以适应大类别数量。
一个标签还是多个标签
Softmax 假设每个样本只属于一个类别。不过,一些样本可以同时属于多个类别的成员。对于此类示例:
- 不能使用 softmax。
- 必须依赖于多个逻辑回归。
例如,上面图 9 中的 1:1 模型假设每个输入图片只能描绘一种水果:苹果、橙子、梨子或葡萄中的一种。然而,如果输入图片可能包含多种类型的水果,就要同时拥有苹果和橙子,这时就要用到回归。