机器学习入门04
今天继续进行机器学习的入门,主题是逻辑回归。
逻辑回归 (Logistic Regression)
逻辑回归模型旨在预测给定结果的概率。许多问题需要将概率估算值(Probability Estimation)作为输出,逻辑回归是一种极其高效的概率计算机制。
Sigmoid函数 (Sigmoid Function)
Sigmoid函数(也称为S型函数, S-shaped Function)是逻辑回归中的核心函数,其数学表达式为:
\[ f(x) = \frac{1}{1 + e^{-x}} \]
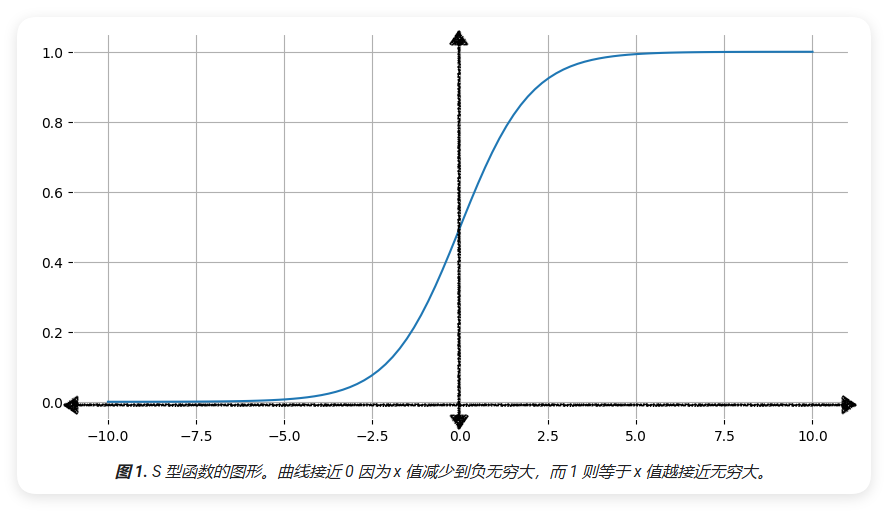
Sigmoid函数具有以下重要特征(Features):
- 输出范围(Output Range):函数值始终在0到1之间,这使其非常适合表示概率
- S形曲线(S-shaped Curve):函数呈现出特征性的S形曲线
- 渐近线(Asymptote):
- 当x趋向正无穷时,f(x)趋近于1
- 当x趋向负无穷时,f(x)趋近于0
- 对称性(Symmetry):函数关于点(0, 0.5)对称
使用Sigmoid函数转换线性输出 (Transform Linear Output)
逻辑回归模型首先计算线性组合(Linear Combination):
\[ z = b + w_1x_1 + w_2x_2 + ... + w_Nx_N \]
其中:
- z 是线性方程的输出 (也称为对数几率, Log-odds)
- b 是偏差项 (Bias)
- w 的值是模型学习的权重 (Weights)
- x 的值是特征样本的特征值 (Feature Values)
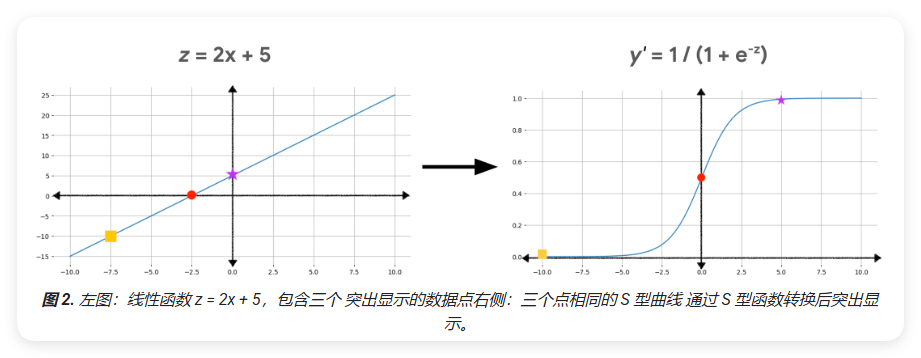
要获得逻辑回归的预测结果,需要将 z 值传递给Sigmoid函数,将得到一个介于0到1之间的值(概率, Probability):
\[ y' = \frac{1}{1 + e^{-z}} \]
其中:
- y' 是逻辑回归模型的输出 (Model Output)
- z 是线性输出(按上述等式计算得出)
逻辑回归 模型的训练过程与 线性回归 两个关键区别:
- 使用 对数损失函数 作为损失函数 而不是平方损失函数。
- 应用正则化 是防止 过拟合。
对数损失函数 (Log Loss Function)
逻辑回归模型的训练过程与线性回归有两个关键区别:
- 使用对数损失函数作为损失函数,而不是平方损失函数。
- 应用正则化防止过拟合。
为什么不使用平方损失函数?
在线性回归中,我们使用平方损失函数(L2 Loss Function)作为损失函数。但对于逻辑回归,平方损失函数并不适合,原因如下:
- 非线性输出:由于Sigmoid函数的非线性特性,当对数几率(z)接近0时,输出(y')的变化幅度比z的变化更大
- 精度问题:下表展示了当输入值从5到10时,输出值和所需精度的变化:
| 输入(Input) | 逻辑输出(Output) | 所需精度位数(Precision) |
|---|---|---|
| 5 | 0.993 | 3 |
| 6 | 0.997 | 3 |
| 7 | 0.999 | 3 |
| 8 | 0.9997 | 4 |
| 9 | 0.9999 | 4 |
| 10 | 0.99998 | 5 |
如果使用平方损失来计算Sigmoid函数的误差,当输出接近0和1时,需要更多的精度位数来保留这些差异。
对数损失函数定义
对数损失函数(Log Loss Function)通过对数形式来返回变化梯度的对数,而不仅是从数值到预测的距离。其计算公式为:
\[ \text{Log Loss} = \sum_{(x,y) \in D} -y\log(y') - (1-y)\log(1-y') \]
其中:
- \((x,y) \in D\) 是包含多个有标签样本的数据集,这些样本为\((x,y)\)对
- \(y\) 是有标签样本中的标签,由于这是逻辑回归,\(y\)的每个值都必须为0或1
- \(y'\) 是模型的预测结果(介于0和1之间),给定集合\(x\)中的功能
逻辑回归中的正则化 (Regularization in Logistic Regression)
什么是正则化?
正则化(Regularization)是用来降低模型复杂度的技术。在逻辑回归研究中,如果没有正则化,逻辑回归的渐近性质会导致全局损失接近0,容易造成过拟合(Overfitting)。
常用的正则化方法
- L2正则化 (L2 Regularization)
- 也称为权重衰减(Weight Decay)
- 通过在损失函数中添加所有特征权重的平方和来实现
- 倾向于让权重变得更小,但不会变成0
- 早停法 (Early Stopping)
- 通过限制训练步数来控制模型复杂度
- 在损失曲线趋于平缓时停止训练
- 可以防止模型过度拟合训练数据
- 需要使用验证集来确定最佳停止时机
以上是逻辑回归的基础内容,后续的内容请看下一篇博客。