机器学习入门05
今天继续进行机器学习的入门,主题是分类。
分类 (Classification)
分类是机器学习中的一种重要任务,其目标是根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类。
阈值(Threshold)和分类决策
在二分类问题中,分类模型通常会输出一个0到1之间的预测值,表示样本属于某个类别的概率。例如,在垃圾邮件分类中,预测值0.75表示该邮件有75%的可能性是垃圾邮件。为了将这个概率值转换为具体的分类结果(垃圾邮件或非垃圾邮件),我们需要设定一个阈值(threshold)。
当我们设定阈值后:
- 如果预测概率大于阈值,样本会被分类为正类(如垃圾邮件)
- 如果预测概率小于阈值,样本会被分类为负类(如正常邮件)
阈值(Threshold)的选择
阈值的选择非常重要,会直接影响分类结果。以垃圾邮件分类为例:
- 如果模型对某封邮件的预测值为0.99,表示它有99%的可能性是垃圾邮件
- 如果另一封邮件的预测值为0.51,表示它有51%的可能性是垃圾邮件
- 如果我们将阈值设为0.5,这两封邮件都会被分类为垃圾邮件
- 但如果将阈值设为0.95,则只有第一封邮件会被分类为垃圾邮件
虽然0.5看起来是一个直观的选择,但在实际应用中,我们需要考虑:
- 不同类别样本的分布是否均衡
- 错误分类的代价是否相同
- 业务需求的具体要求
例如,如果将正常邮件错误地归类为垃圾邮件的代价远高于将垃圾邮件错误地归类为正常邮件,我们可能需要设置一个较高的阈值,以减少误判正常邮件的情况。
混淆矩阵(Confusion Matrix)
在评估分类模型的性能时,仅仅知道预测概率是不够的,我们还需要了解模型预测的具体情况。混淆矩阵(Confusion Matrix)是一个非常有用的工具,它可以帮助我们详细了解分类器的预测结果。
混淆矩阵可以用下表表示:
| 实际正例 | 实际负例 | |
|---|---|---|
| 预测为正 | 真正例(TP): 被正确分类为垃圾邮件的垃圾邮件。这些是系统自动发送到"垃圾邮件"文件夹的垃圾邮件。 | 假正例(FP): 非垃圾邮件被误分类为垃圾邮件。这些是最终进入"垃圾邮件"文件夹的正常电子邮件。 |
| 预测为负 | 假负例(FN): 垃圾邮件被错误分类为非垃圾邮件。这些是垃圾邮件过滤器未捕获的垃圾邮件,并已进入收件箱。 | 真负例(TN): 非垃圾邮件被正确分类为非垃圾邮件。这些是直接发送到收件箱的正常电子邮件。 |
在二分类问题中,混淆矩阵包含四种可能的预测结果:
- 真正例(True Positive, TP): 正确地将正类样本预测为正类
- 例如:正确地将垃圾邮件识别为垃圾邮件
- 假正例(False Positive, FP): 错误地将负类样本预测为正类
- 例如:错误地将正常邮件判定为垃圾邮件
- 假负例(False Negative, FN): 错误地将正类样本预测为负类
- 例如:错误地将垃圾邮件判定为正常邮件
- 真负例(True Negative, TN): 正确地将负类样本预测为负类
- 例如:正确地将正常邮件识别为正常邮件
混淆矩阵的一个重要特点是:
- 每一行的总和(TP + FP 和 FN + TN)代表模型预测的结果分布
- 每一列的总和(TP + FN 和 FP + TN)代表实际的类别分布
数据不平衡问题
在实际应用中,我们经常会遇到数据不平衡的情况,即不同类别的样本数量差异很大。例如,在垃圾邮件分类中,正常邮件可能远多于垃圾邮件。这种不平衡会影响模型的性能评估和训练效果。
如果实际正例的总数与实际负例的总数相差较大,我们称之为数据不平衡。这种情况下,仅仅依靠准确率可能会产生误导。 例如,在一个数据集中,如果只有1%的邮件是垃圾邮件,那么一个简单地将所有邮件都判定为正常邮件的模型也能获得99%的准确率,但这显然不是一个好的模型。
分类评估指标
在分类问题中,我们需要一些指标来评估模型的性能。这些指标基于混淆矩阵中的不同组成部分计算得出,并且会随着阈值的设置而变化。通常,用户会根据具体任务调整阈值来优化某个指标。
准确率(Accuracy)
准确率是最基本的分类评估指标,它表示所有分类(无论是正类还是负类)中正确分类的比例。其数学定义为:
\[ Accuracy = \frac{correct\ classifications}{total\ classifications} = \frac{TP + TN}{TP + TN + FP + FN} \]
在垃圾邮件分类示例中,准确率衡量的是所有电子邮件正确分类所占的比例。
一个完美的模型没有假正例和假负例,因此准确率为1.0,即100%。
由于准确率包含混淆矩阵中的所有四种结果(TP、FP、TN、FN),因此在数据集平衡且各个类别中的示例数量相近的情况下,准确率可以用作衡量模型质量的相对指标。因此,它通常是许多通用或未指定任务的通用或未指定模型使用的默认评估指标。
然而,如果数据集不平衡,或者一种错误(假负例或假正例)的代价高于另一种错误(大多数实际应用中都是如此),则最好改为对其他指标进行优化。
例如,对于严重不均衡的数据集(其中一个类别出现的频率非常低,例如1%),如果模型100%都预测为负类,则准确率得分为99%,尽管该模型毫无用处。
注意:在机器学习(ML)中,recall、precision和accuracy等字词的数学定义可能与这些字词的常用含义不同,或更具体。
召回率或真正例率(Recall or TPR)
召回率(Recall),也称为真正例率(True Positive Rate, TPR),表示在所有实际正例中被正确分类为正例的比例。其数学定义为:
\[ Recall\ (TPR) = \frac{correctly\ classified\ actual\ positives}{all\ actual\ positives} = \frac{TP}{TP + FN} \]
在垃圾邮件分类示例中,召回率衡量的是被正确分类为垃圾邮件的垃圾邮件的比例。因此,召回率的另一个名称是检测概率:它回答了"此模型检测到垃圾邮件的比例是多少?"这一问题。
一个完美的模型,其假负例率为0,因此召回率(TPR)为1.0,也就是说,检测率为100%。
在实际正例数量非常少(例如总共1-2个样本)的不平衡数据集中,召回率作为指标的意义不大,作用不大。
假正例率(FPR)
假正例率(False Positive Rate, FPR)是指被错误分类为正例的所有实际负例所占的比例,也称为误报概率。其数学定义为:
\[ FPR = \frac{incorrectly\ classified\ actual\ negatives}{all\ actual\ negatives} = \frac{FP}{FP + TN} \]
假正例是被错误分类的实际负例,因此会出现在分母中。在垃圾邮件分类示例中,FPR用于衡量被错误分类为垃圾邮件的合法电子邮件的比例,或模型的误报率。
完美的模型没有假正例,因此FPR为0.0,也就是说,假警报率为0%。
在实际负例数量非常少(例如总共1-2个示例)的不平衡数据集中,FPR作为一个指标就没有那么有意义和实用。
精确率(Precision)
精确率是指模型所有正分类分类中实际正分类的比例。在数学上,其定义为:
\[ Precision = \frac{correctly\ classified\ actual\ positives}{everything\ classified\ as\ positive} = \frac{TP}{TP + FP} \]
在垃圾邮件分类示例中,精确率衡量的是被归类为垃圾邮件的电子邮件中实际是垃圾邮件的比例。
假设有一个完美的模型,则该模型没有假正例,因此精确率为1.0。
在实际正例数量非常少(例如总共1-2个示例)的不平衡数据集中,精确率作为指标的意义和实用性较低。
随着假正例的减少,精确率会提高;随着假负例的减少,召回率会提高。但正如前面所述,提高分类阈值往往会减少正例的数量并增加假负例的数量,而降低阈值则会产生相反的效果。因此,精确率和召回率通常呈反向关系,提高一个会反过来降低另一个。
指标的选择和权衡
在评估模型和选择阈值时,选择优先处理的指标取决于特定问题的需求、收益和风险。在垃圾邮件分类示例中,通常最好优先考虑召回率(抓取所有垃圾邮件)或准确率(尽量确保被标记为垃圾邮件的电子邮件实际上是垃圾邮件),或者在达到某个最低准确性水平的情况下,兼顾这两者。
| 指标 | 指南 |
|---|---|
| 准确率 | 作为平衡数据集的模型训练进度/收敛情况的粗略指标。 对于模型效果,请仅与其他指标结合使用。 避免使用不平衡的数据集,考虑使用其他指标。 |
| 召回率 (真正例率) |
在假负例比假正例开销更高时使用。 |
| 假正例率 | 在假正例比假负例开销更高时使用。 |
| 精确率 | 当正例预测的准确性非常重要时,请使用此方法。 |
F1 得分
F1 得分是精确率和召回率的调和平均数(一种平均值)。
在数学上,它可以按下式计算:
\[ F1 = 2 * \frac{precision * recall}{precision + recall} = \frac{2TP}{2TP + FP + FN} \]
该指标在精确率和召回率的重要性之间进行了平衡,对于类别不平衡的数据集,该指标优于准确率。如果精确率和召回率的完美分数均为 1.0,则F1 的完美分数也是 1.0。更广泛地说,当精确率和召回率的值接近时,F1 也会接近它们的值。当精确率和召回率相差很大时,F1 将与较差的指标相似。
ROC 和曲线下面积
接收者操作特征曲线(ROC)
ROC 曲线是模型在所有阈值上的表现的可视化表示。这个长版名称(即接收器操作特征)来自二战雷达侦测工具。
ROC 曲线的绘制方法是计算真正例率(TPR) 和假正例率(FPR) 值(在实践中,通常绘制 FPR 对 TPR 图表。完美的模特在某些阈值下,TPR 为 1.0,FPR 为 0.0,都表示为(0, 1)(如果所有其他阈值均被忽略),或者出现如下情况:
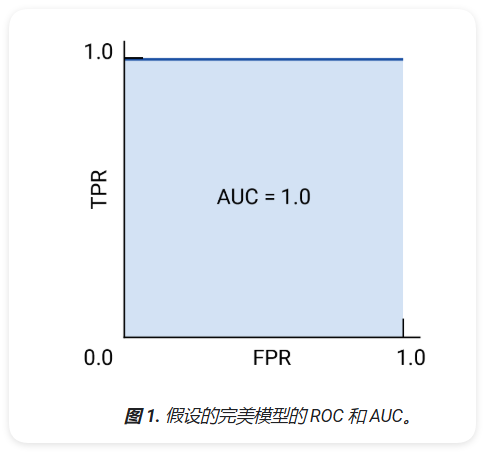
曲线下面积 (AUC)
ROC 曲线下面积 (AUC) 表示模型的概率,如果给定一个随机选择的正类别和负类别样本,正值将大于负值。
上述完美模型包含一个边长为 1 的正方形,曲线下面积(AUC) 为 1.0。也就是说,有 100% 的可能性模型会正确地将随机选择的正例排列在随机选择的负例之前。换句话说,如果观察 ROC 给出了模型将随机选择的阈值右侧的平方,与阈值。
具体而言,使用 AUC 的垃圾邮件分类器则随机分配垃圾邮件的概率始终较高,随机生成合法电子邮件每个单元的实际分类取决于您选择的阈值。
对于二元分类器来说,一个模型与随机猜测相比较的 ROC,它是一条从 (0,0) 到 (1,1) 的对角线。曲线下面积为 0.5,表示对某个随机正例进行排名的概率为 50%,反例。
在垃圾邮件分类器示例中,AUC 为 0.5 的垃圾邮件分类器将随机发送垃圾邮件的概率要高于随机发送的垃圾邮件 合法电子邮件只占一半的时间。
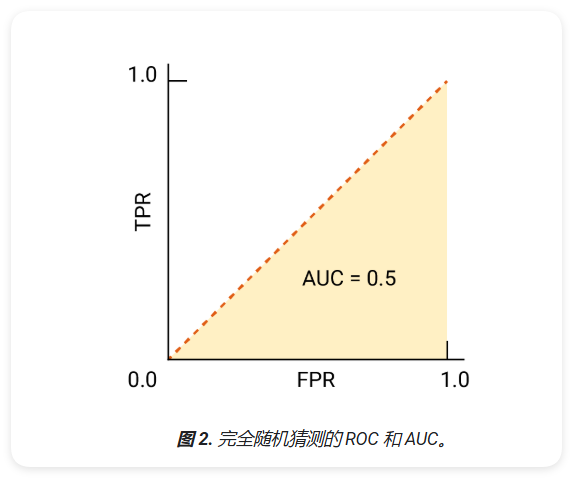
精确率与召回率曲线
AUC 和 ROC 非常适合在数据集大致如下的情况下比较模型不同类别之间的平衡。当数据集不平衡时,精确率与召回率以及这些曲线下方区域的面积可能会提供直观呈现模型性能的精确率/召回率曲线由 y 轴的精确率和 x 轴的召回率构成。
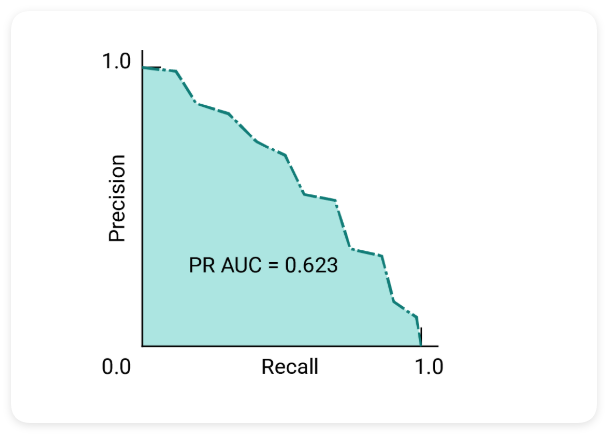
用于选择模型和阈值的 AUC 和 ROC
曲线下面积是一个非常有用的指标,用于比较两个不同模型,只要数据集大致均衡即可。(请参阅精确率与召回率曲线,针对不平衡的数据集。)下方是较大区域,那么曲线通常效果最佳:
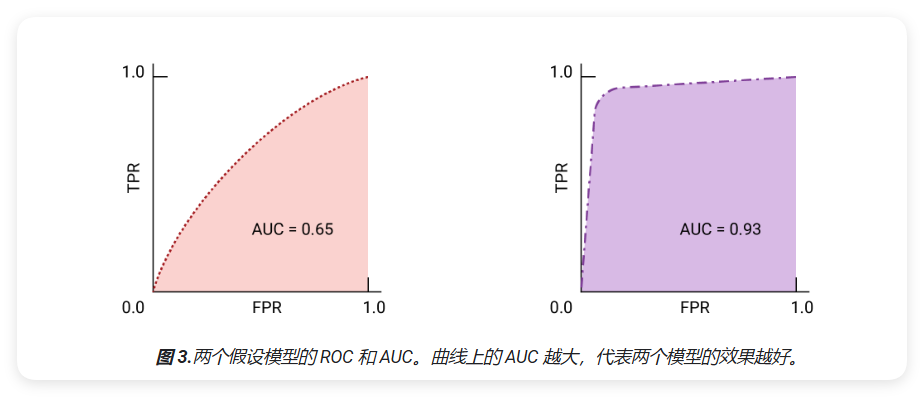
ROC 曲线上最接近 (0,1) 的点表示指定模型表现最佳的阈值,正如阈值、温度矩阵和指标选择和权衡中所述。选择阈值取决于对应用而言最重要的指标。具体用例,请考虑以下要点 A、B 和 C 示意图,每个选项代表一个阈值:
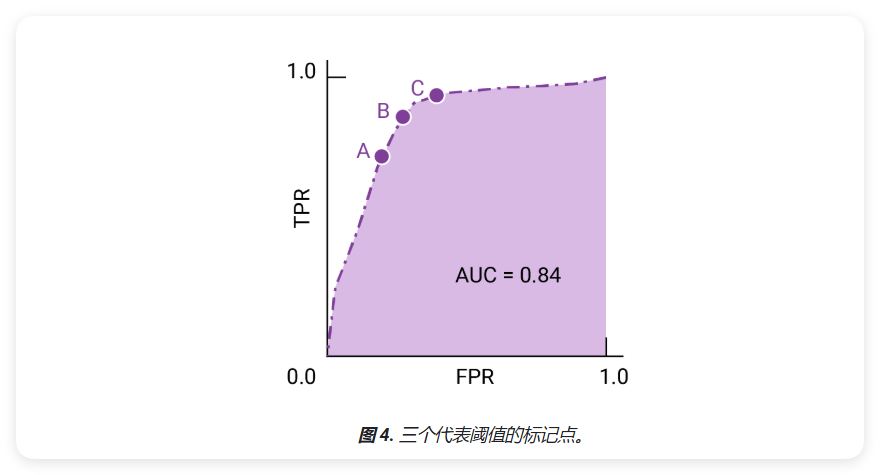
如果误报(误报)的代价很高,即使 TPR,相反,如果假正例费用低廉,(错失的真正例)代价很高,C 点的阈值可以最大限度提高 TPR,可能更合适。如果费用大致相等,请确保 B 点可在 TPR 和 FPR 之间实现最佳平衡。
预测偏差(Prediction Bias)
预测偏差是指模型预测值的平均值与标签数据中观察到的真实平均值之间的差异。它可以帮助我们发现模型训练过程中存在的系统性问题。
预测偏差的计算
预测偏差的计算公式为:
\[ Prediction\ Bias = Average\ of\ Predictions - Average\ of\ Labels \]
例如,在垃圾邮件分类问题中:
- 如果在标签数据中有5%的邮件是垃圾邮件(即标签平均值为0.05)
- 而模型对所有邮件的预测值平均为0.05
- 则预测偏差为0,表明模型预测结果与实际分布相符
相反,如果模型预测50%的邮件是垃圾邮件,而实际只有5%,这就表明模型存在显著的预测偏差。
预测偏差的常见原因
- 数据质量问题
- 训练数据中的噪声或错误
- 特征数据的不完整或不准确
- 标签数据的质量问题
- 模型问题
- 模型过度拟合(overfitting)
- 特征工程不充分
- 模型复杂度不足
- 训练问题
- 训练过程中的bug
- 学习率设置不当
- 训练轮数不足
- 特征集问题
- 特征集不足以表达目标任务
- 关键特征的缺失
- 特征之间的强相关性
多类别分类(Multi-class Classification)
多类别分类是分类问题的一种重要类型,用于处理具有两个以上类别的分类任务。与二元分类只需区分两个类别不同,多类别分类需要在多个类别中进行选择。
与二元分类的关系
多类别分类可以看作是二元分类的扩展。实际上,很多多类别分类问题可以通过将其分解为一系列二元分类问题来解决。常见的分解策略包括:
- 一对多(One-vs-All):为每个类别训练一个二元分类器
- 一对一(One-vs-One):为每对类别训练一个二元分类器
解决方法示例
以一个包含A、B、C三个类别的分类问题为例:
- 第一步:建立第一个二元分类器,将样本分为(A+B)类和C类
- 第二步:对于被分类为(A+B)的样本,使用第二个二元分类器将其进一步分为A类和B类
通过这种方式,我们就将一个三类别的分类问题转化为两个二元分类问题。
应用实例
多类别分类在实际应用中非常普遍,典型的例子包括:
- 手写数字识别:需要将输入图像分类为0-9这10个数字类别
- 图像分类:识别图片中的不同物体类别
- 新闻分类:将新闻文章分类到不同的主题类别
需要注意的是,在某些应用场景中,一个样本可能同时属于多个类别,这种情况被称为多标签分类问题。
分类:编程练习
在开始编程实践之前,我们需要准备好必要的Python库。这些库将帮助我们完成数据处理、模型训练和结果可视化等任务。
环境准备
首先导入所需的Python库:
1 | # 数据处理和分析 |
加载数据集
在这个练习中,我们将使用一个大米品种分类数据集。这个数据集包含了两种不同品种大米(Cammeo和Osmancik)的图像特征数据。
首先,让我们从Google的机器学习教育数据集库中加载数据:
1 | # 从在线源加载大米品种数据集 |
数据集的基本统计信息:
| 统计量 | Area | Perimeter | Major_Axis_Length | Minor_Axis_Length | Eccentricity | Convex_Area | Extent |
|---|---|---|---|---|---|---|---|
| count | 3810.0 | 3810.0 | 3810.0 | 3810.0 | 3810.0 | 3810.0 | 3810.0 |
| mean | 12667.7 | 454.2 | 188.8 | 86.3 | 0.9 | 12952.5 | 0.7 |
| std | 1732.4 | 35.6 | 17.4 | 5.7 | 0.0 | 1777.0 | 0.1 |
| min | 7551.0 | 359.1 | 145.3 | 59.5 | 0.8 | 7723.0 | 0.5 |
| 25% | 11370.5 | 426.1 | 174.4 | 82.7 | 0.9 | 11626.2 | 0.6 |
| 50% | 12421.5 | 448.9 | 185.8 | 86.4 | 0.9 | 12706.5 | 0.6 |
| 75% | 13950.0 | 483.7 | 203.6 | 90.1 | 0.9 | 14284.0 | 0.7 |
| max | 18913.0 | 548.4 | 239.0 | 107.5 | 0.9 | 19099.0 | 0.9 |
这个数据集包含了大米颗粒的各种形态特征,如面积、周长、长度、宽度等,可以用来训练一个分类模型来区分不同的大米品种。
数据可视化
为了更好地理解数据集中各个特征之间的关系,我们可以创建散点图来进行可视化分析。以下代码将创建5个不同的散点图,展示不同特征对之间的关系:
1 | # 创建5个2D散点图,展示不同特征之间的关系 |
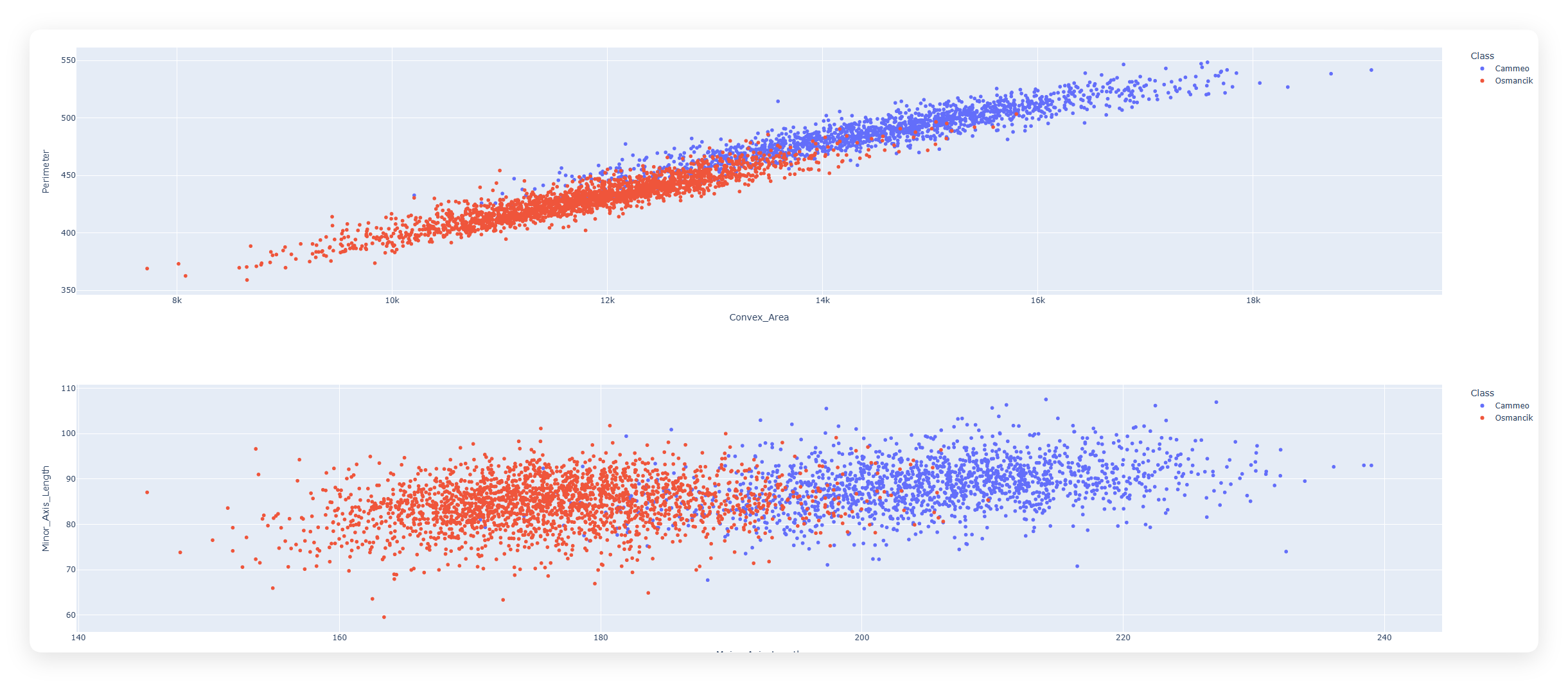
通过这些散点图,我们可以直观地观察到不同品种大米在这些特征上的分布差异,这对于后续的分类模型构建有重要的参考价值。
除了2D散点图,我们还可以使用3D散点图来同时观察三个特征之间的关系。这样可以提供更全面的视角来理解数据分布:
1 | # 创建3D散点图 |
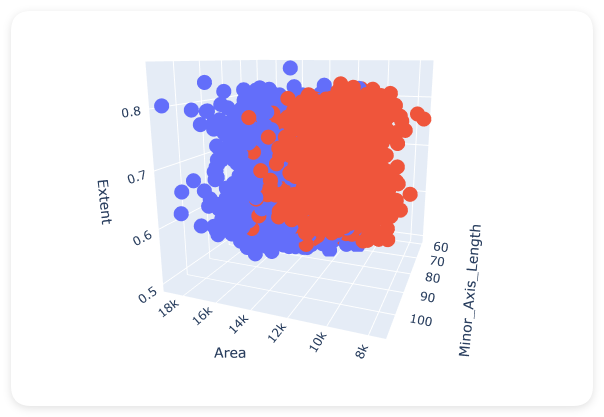
通过3D可视化,我们可以更直观地观察到这些特征是如何共同作用来区分不同品种的大米。这种多维度的观察对于理解特征之间的相互关系以及它们在分类中的重要性非常有帮助。
数据标准化
在开始训练模型之前,我们需要对数据进行标准化处理。标准化可以使不同尺度的特征具有可比性,有助于提高模型的训练效果。这里我们使用Z-score标准化方法:
1 | # 计算每个数值特征的Z-score |
通过Z-score标准化,大部分数据会落在[-2, +2]的区间内,这有助于模型更好地学习特征之间的关系。
Z-score标准化是一种常用的数据标准化方法,也称为标准分数标准化。它通过计算每个数据点与平均值的差异,再除以标准差来实现标准化:
Z = (x - μ) / σ
其中: - x 是原始数据点 - μ 是数据集的平均值 - σ 是数据集的标准差
经过Z-score标准化后: - 数据的平均值变为0 - 标准差变为1 - 大约68%的数据落在[-1, +1]区间内 - 大约95%的数据落在[-2, +2]区间内
数据集准备
在开始训练模型之前,我们需要对数据集进行一系列准备工作:
1 | # 设置随机种子以确保结果可重现 |
这个准备过程包含几个重要步骤:
- 标签编码
- 将文本标签(Cammeo/Osmancik)转换为数值(1/0)
- 便于模型处理和计算
- 数据集分割
- 训练集(80%): 用于模型训练
- 验证集(10%): 用于调整模型参数
- 测试集(10%): 用于评估最终模型性能
- 随机打乱
- 确保数据的随机性
- 避免数据中可能存在的顺序偏差
- 特征标签分离
- 将特征和标签分开
- 符合机器学习模型的输入要求
模型构建与训练函数
为了实现模型的创建和训练,我们定义了以下关键类和函数:
1 | # 实验设置类,用于存储模型的超参数和输入特征 |
模型训练实施
在定义好模型结构后,我们开始进行具体的训练过程: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51# 设置模型训练参数
settings_all_features = ExperimentSettings(
learning_rate=0.001, # 学习率
number_epochs=60, # 训练轮数
batch_size=100, # 批次大小
classification_threshold=0.5, # 分类阈值
input_features=all_input_features, # 输入特征
)
# 定义评估指标
metrics = [
# 准确率
keras.metrics.BinaryAccuracy(
name='accuracy',
threshold=settings_all_features.classification_threshold,
),
# 精确率
keras.metrics.Precision(
name='precision',
thresholds=settings_all_features.classification_threshold,
),
# 召回率
keras.metrics.Recall(
name='recall',
thresholds=settings_all_features.classification_threshold
),
# AUC曲线
keras.metrics.AUC(num_thresholds=100, name='auc'),
]
# 创建模型
model_all_features = create_model(settings_all_features, metrics)
# 训练模型
experiment_all_features = train_model(
'all features',
model_all_features,
train_features,
train_labels,
settings_all_features,
)
# 绘制训练过程中的指标变化
plot_experiment_metrics(
experiment_all_features,
['accuracy', 'precision', 'recall']
)
plot_experiment_metrics(
experiment_all_features,
['auc']
)
这个训练过程包含以下关键要素:
- 训练参数设置
- 学习率(0.001): 控制模型参数更新的步长
- 训练轮数(60): 完整数据集的训练次数
- 批次大小(100): 每次更新使用的样本数
- 分类阈值(0.5): 二分类的判定界限
- 评估指标选择
- 准确率(Accuracy): 正确分类的样本比例
- 精确率(Precision): 预测为正的样本中实际为正的比例
- 召回率(Recall): 实际为正的样本中被正确预测的比例
- AUC: 反映模型的整体分类性能
- 训练过程监控
- 通过可视化观察各项指标的变化趋势
- 及时发现过拟合或欠拟合问题
- 评估模型训练的收敛情况
模型性能评估
为了全面评估模型的性能,我们需要在测试集上进行评估并与训练集结果进行比较:
1 | # 在测试集上评估模型性能 |
以上是分类的基础内容,后续的内容请看下一篇博客。