机器学习入门11
今天继续进行机器学习的入门,主题是大语言模型。
大语言模型(LLM)
大语言模型(LLM)简介
大语言模型(Large Language Model)是一种基于深度学习的自然语言处理模型,它能够处理和生成大量的文本数据。LLM 通常使用 Transformer 架构,这种架构在自然语言处理任务中表现出色。
LLM 相比传统语言模型有以下优势: 1. 参数量更大,学习能力更强 2. 可以处理更长的上下文 3. 能够完成多种复杂的语言任务
令牌(Token)
令牌是文本的最小单位,通常是单词或子词。令牌化是将文本转换为令牌序列的过程。让我们通过具体例子来理解:
常见令牌化方法
- 按空格分词:
- 适用于英文等使用空格分隔的语言
- 例:
"deep learning"→["deep", "learning"]
- 基于规则分词:
- 使用字典和语言规则
- 适用于中文等无明显分隔符的语言
- 例:
"人工智能"→["人工", "智能"]
- 子词分词:
- 将长单词拆分成常用部分
- 例:
"unhappy"→["un", "happy"] - 可以减少词表大小,处理未知词
N元语法语言模型
N元语法是一种用于构建语言模型的序列预测方法,其中N表示序列中的单词数。这种模型通过观察前面N-1个单词来预测下一个可能出现的单词。
基本概念
- 2元语法(bigram):
- N = 2时的语言模型
- 使用前一个单词预测下一个单词
- 例如:"you are very nice" 可以生成以下2-gram:
- "你是"
- "非常"
- "非常好"
- 3元语法(trigram):
- N = 3时的语言模型
- 使用前两个单词预测下一个单词
- 例如对相同的词组,得到的三元语法为:
- "你非常"
- "非常好"
预测机制
- 上下文依赖:
- 给定前面的单词作为输入
- 基于N元语法预测下一个单词
- 例如:"orange is" 可能的下一个单词:
- "orange is ripe"(水果相关)
- "orange is cheerful"(颜色相关)
- 预测特点:
- 模型会检查训练数据中的所有相关N-gram
- 根据上下文选择最可能的后续单词
- 考虑语义和使用频率
- 应用考虑:
- N值越大,考虑的上下文越多
- 但也需要更大的训练数据集
- 需要平衡准确性和计算复杂度
通过N元语法模型,我们可以实现基于上下文的文本预测,这在自然语言处理中是一项重要的基础技术。
上下文在语言模型中的作用
上下文的基本概念
- 人类语言理解:
- 人类可以保留相对较长的上下文
- 理解对话需要记住之前的信息
- 上下文帮助理解语言的真实含义
- 语言模型中的应用:
- 上下文是自标注标签
- 帮助模型确定词语的具体含义
- 例如:"orange is" 可以根据上下文判断是水果还是颜色
N元语法的上下文限制
- 上下文窗口:
- N元语法只能看到固定长度的上下文
- 三元语法只能看到前两个词
- 有限的上下文导致预测准确性受限
- N值的影响:
- N值越大,考虑的上下文越多
- 但实际出现的组合会减少
- 需要在上下文长度和实用性之间平衡
循环神经网络(Recurrent Neural Network, RNN)的优势
- 长期依赖:
- 循环神经网络可以处理更长的上下文
- 能够学习词语之间的长距离关系
- 更接近人类的语言理解方式
- 实际应用限制:
- 可能遇到梯度消失问题
- 训练时间较长
- 需要大量数据支持
- 与N元语法对比:
- 循环神经网络能学习更多上下文
- 但实际应用中可能受限
- N元语法更简单但上下文有限
通过合理利用上下文信息,语言模型可以更好地理解和生成自然语言,但不同类型的模型在处理上下文时各有优势和限制。
Transformer 架构
Transformer 是一种专门用于处理序列数据(如自然语言)的神经网络架构。它主要由编码器(Encoder)和解码器(Decoder)两部分组成。
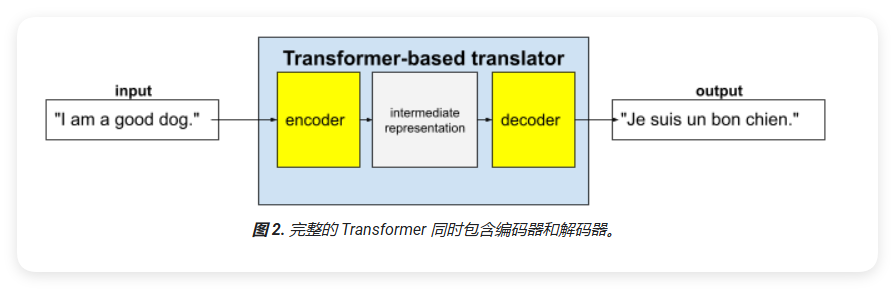
编码器和解码器的工作原理
- 编码器(Encoder):
- 将输入文本转换为中间表示形式
- 使用神经网络进行特征提取
- 例如:将英语句子转换为中间表示
- 解码器(Decoder):
- 将中间表示转换为目标输出
- 同样使用神经网络进行处理
- 例如:将中间表示转换为法语句子
应用示例
以机器翻译为例: 1. 编码器接收输入文本(如英语句子)并处理成中间表示形式 2. 解码器将这个中间表示转换为目标语言(如法语句子) 3. 整个过程是端到端的,不需要人工设计特征
Transformer 架构的优势在于它能够并行处理输入序列,并且能够捕捉序列中的长距离依赖关系,这使它在各种自然语言处理任务中都能取得优秀的表现。
什么是自注意力?
自注意力(Self-Attention)是 Transformer 架构中的一个核心概念,用于增强模型对上下文的理解能力。自注意力机制会为每个输入令牌计算与其他令牌的关联程度。
工作原理
- 基本问题:
- 对于输入的每个令牌,需要回答:"这个令牌与序列中其他令牌的关系如何?"
- 自注意力机制通过计算令牌之间的关联度来回答这个问题
- 处理过程:
- 计算输入序列中所有令牌之间的关系
- 特别关注令牌之间的语义联系
- 生成考虑了上下文的表示
实际示例
让我们通过一个具体的例子来理解:
The animal didn't cross the street because it was too tired.
在这个句子中:
- 句子包含 11 个单词
- 每个单词都需要与其他 10 个单词建立关联
- 特别注意代词 "it" 的处理:
- "it" 指代的是 "animal"(动物)
- 自注意力机制能够识别出这种指代关系
- 通过计算关联度,确定 "it" 更可能指代 "animal" 而不是其他词
自注意力机制的优势在于它能够:
- 自动学习序列中的重要关系
- 处理长距离依赖
- 提供更好的上下文理解
通过这种机制,Transformer 能够更好地理解文本的语义结构,从而在各种自然语言处理任务中取得优秀表现。
多头自注意力机制
多头自注意力(Multi-Head Attention)是对基本自注意力机制的扩展,通过并行计算多个注意力"头"来捕捉不同类型的关系。
工作原理
- 基本结构:
- 每个自注意力层由多个注意力头组成
- 每个头独立计算不同的注意力分数
- 最终输出是不同头的结果组合(例如加权平均值或点积)
- 多头的优势:
- 可以学习不同类型的关系
- 增强模型的表达能力
- 允许并行处理,提高效率
实际应用示例
以前面的例子为例:
The animal didn't cross the street because it was too tired.
在这个句子中: - 不同的注意力头可以关注不同的语言特征: * 一些头可能专注于代词"it"与"street"的关系 * 其他头可能关注"animal"与动词的关系 * 还有的头可能学习句法结构
通过多头自注意力机制,Transformer能够: 1. 同时捕捉多种语言特征 2. 提高模型的理解能力 3. 生成更丰富的语言表示
LLM的训练方法
大语言模型(LLM)的训练过程主要基于大量文本数据,采用非监督学习的方式进行。这种训练方法有其独特的特点和优势。
非监督学习训练
- 基本原理:
- 模型通过预测被遮掩的文本来学习
- 不需要人工标注的训练数据
- 可以利用互联网上大量的自然文本
- 掩码预测示例:
1
2
3
4
5原始文本:
The residents of the sleepy town weren't prepared for what came next.
掩码后的文本:
The ___ of the sleepy town weren't prepared for ___ came next.
训练过程
掩码机制:
- 系统随机遮掩部分词语
- 模型需要预测被遮掩的内容
- 通过大量练习提高预测准确度
实际训练例子:
1
2
3
4
5原始文本:
Oranges are traditionally harvested by hand. Once clipped from a tree, they don't ripen.
掩码文本:
Oranges are traditionally ___ by hand. Once clipped from a tree, __ don't ripen.在这个例子中:
- "harvested"或"picked"是第一个空位的高概率选项
- "oranges"或"they"是第二个空位的合理选择
训练效果
- 模型能力:
- 学习语言的自然模式
- 理解上下文关系
- 生成合理的预测
- 优化方向:
- 通过指令优化提高性能
- 增强模型的理解能力
- 提高预测准确度
通过这种训练方式,LLM能够学习语言的深层结构和语义关系,从而在各种自然语言处理任务中表现出色。
LLM的文本生成能力
基本原理
LLM本质上是一个自动补全系统,能够基于上下文生成合适的文本。它通过预测和生成来完成各种文本任务。
生成示例
句子补全:
1
2
3
4
5
6输入:
My dog, Max, knows how to perform many traditional dog tricks.
可能的补全:
- He can sit down, stay in place and roll over. (概率:3.1%)
- He has learned to sit down, stay in place and roll over. (概率:2.9%)问答生成:
1
2用户问题:What is the easiest trick to teach a dog?
LLM回答:[生成相关回答]
生成特点
- 概率模型:
- LLM为每个可能的补全生成概率
- 选择最合适的文本进行输出
- 考虑上下文和语义关联
- 应用范围:
- 文本补全
- 问答对话
- 内容创作
- 数据处理
- 局限性:
- 生成内容基于训练数据
- 需要合适的提示和上下文
- 可能需要人工验证和修正
通过这种方式,LLM能够生成连贯、相关的文本内容,但其本质仍是基于统计模型的文本生成系统。
LLM的微调过程
LLM的基本类型
- 基础LLM:
- 使用大规模自然语言进行训练
- 理解基本语法和语言规则
- 可以完成基础创造性任务
- 适合作为基础平台使用
- 特点和局限:
- 输出不一定符合具体应用需求
- 难以解决特定类型问题
- 如回归或分类等任务表现有限
微调(Fine-tuning)
微调是一种通过少量数据调整预训练模型参数的方法,以适应特定任务。
- 参数数量:
- 不会改变模型的参数数量
- 保持原始模型结构不变
- 参数调整:
- 只调整现有参数的值
- 微调参数以适应新任务
- 主要目的:
- 让模型更好地适应特定任务
- 提高特定领域的性能表现
LLM的蒸馏(Distillation)
蒸馏是一种将大型语言模型(LLM)转换为较小、更高效版本的技术。它通过创建一个较小的学生模型来模仿原始大型模型的行为,从而在保持模型性能的同时减少计算资源的使用。
- 模型规模:
- 创建参数更少的模型
- 显著减少模型体积
- 知识保持:
- 通过知识迁移保持核心功能
- 维持关键能力不丢失
- 优化目标:
- 得到更小但仍有效的模型
- 平衡模型大小和性能表现
LLM的提示工程
基本概念
提示工程是让LLM的最终用户自定义模型输出的方法,通过向LLM展示如何对提示做出响应来实现。
提示类型和示例
单样本提示:
1
用户输入水果的名称:LLM 输出该水果的类。
简单示例:
1
2peach: drupe
apple: ______LLM可能的输出:
1
apple: pome
多样本示例:
1
2
3plum: drupe
pear: pome
lemon: ____
提示工程特点
- 使用方式:
- 可以使用单个或多个示例
- 示例应清晰表达期望输出
- 可以组合不同类型的提示
- 零样本问题:
- LLM可以在没有示例的情况下预测
- 需要清晰的上下文
- 预测质量可能受影响
- 注意事项:
- 提示工程不会改变模型的参数
- 主要利用模型的理解能力
- 选择合适的提示方式很重要