机器学习入门10
今天继续进行机器学习的入门,主题是嵌入(Embedding)。
稀疏数据表示法的问题
在研究独热编码时,我们需要注意数据表示形式带来的两个主要问题:
权重数量过大:输入向量大小与神经网络权重直接相关。当使用 M 个类目的独热编码时,模型必须训练该层的 M×N 权重矩阵。这会导致以下问题:
数据需求增加:模型的权重越多,需要的训练数据就越多,才能进行有效训练。
计算开销增大:权重增多导致所需的计算量显著增加,影响模型的训练和使用效率。
内存占用提高:模型中的权重越多,训练和处理时的内存需求就越大,这可能成为扩展规模的瓶颈。
设备兼容性受限:在设备端机器学习(ODML)场景下,如果您希望在本地设备上运行模型(而不是依赖云计算),就需要考虑减少权重数量。
向量间缺乏语义关联:输入的独热编码向量之间没有体现实际事物的相似度。从数学角度来说,索引1("热狗")与索引2("沙拉")的距离,等同于与索引4999("沙威玛")的距离,但实际上狗肉与沙拉的相似度要远低于沙拉与沙威玛(均为食品)的相似度。
在接下来的内容中,我们将学习如何通过嵌入(Embedding)技术来解决这些问题。
嵌入(Embedding)技术
什么是嵌入?
嵌入是一种将高维稀疏向量(如独热编码)转换为低维密集向量的技术。它不仅可以解决维度灾难问题,还能通过学习捕获数据之间的语义关系。
为什么需要嵌入?
- 降低维度:
- 将高维稀疏向量(如1000维独热编码)映射到低维空间(如8维向量)
- 显著减少模型需要学习的权重数量
- 降低内存占用和计算开销
- 捕获语义关系:
- 在嵌入空间中,相似的事物会被映射到相近的位置
- 例如:"热狗"和"汉堡"的嵌入向量会比"热狗"和"笔记本"的更接近
- 这种语义关系可以帮助模型做出更好的预测
降维技术与嵌入
降维技术基础
降维技术是一类可以在低维空间中捕获高维数据重要结构的数学方法。这些方法可以用作机器学习系统的嵌入基础,其中最典型的例子是主成分分析(PCA):
- PCA的应用:
- 用于创建词嵌入
- 给定一组实例(如词袋向量)
- 寻找最能保留原始数据信息的低维表示
嵌入层的训练过程
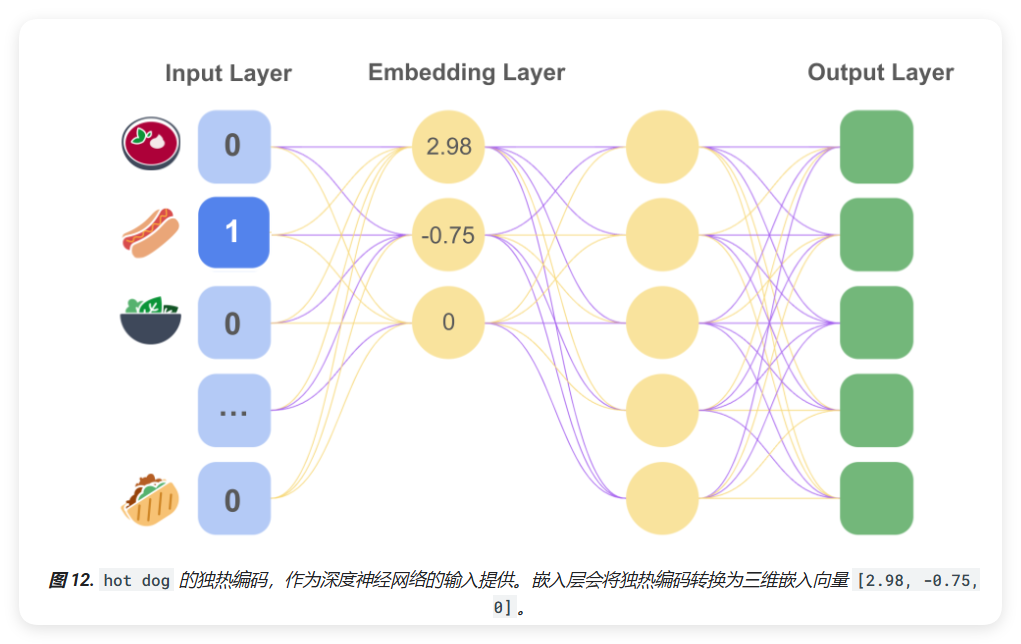
- 嵌入层设置:
- 在神经网络中创建大小为d的嵌入层
- d表示嵌入空间的维度(隐藏层节点数)
- 嵌入层可以与其他网络层组合使用
- 训练机制:
- 嵌入层参数随机初始化
- 通过反向传播优化嵌入参数
- 目标是最小化网络输出层的预测误差
- 优化过程:
- 神经网络学习第一个隐藏层(嵌入层)中节点的权重
- 权重反映了输入特征之间的关系
- 通过训练捕获数据的语义相似度
实际应用案例:食品推荐系统
- 数据准备:
- 收集用户喜好的食品数据
- 将问题转化为监督学习任务
- 构建食品特征的嵌入表示
- 模型构建:
- 设置食品的特征向量
- 使用嵌入层降维处理
- 应用softmax进行多类别预测
- 训练效果:
- 相似食品在嵌入空间中距离接近
- 例如:"热狗"的独热编码输入可以转换为更有意义的低维向量
- 这种表示能够更好地捕获食品之间的相似关系
通过这种方式,嵌入层不仅降低了数据维度,还学习到了数据之间的语义关系,使得模型能够更好地理解和预测用户的喜好。
情境嵌入(Contextual Embedding)
静态嵌入的局限性
- word2vec的基本限制:
- 每个词只对应一个固定的向量表示
- 无法处理一词多义的情况
- 忽略了词语在不同语境下的含义变化
- 实际应用中的问题:
- 例如"橙色"一词可能表示颜色或水果
- 在静态嵌入中,这两种含义会被混合在一个向量中
- 降低了模型对语义的理解能力
情境嵌入的优势
- 动态表示:
- 根据上下文动态生成词向量
- 同一个词在不同语境下有不同的表示
- 更好地捕捉词语的实际含义
- 上下文信息整合:
- 考虑周围词语的语义信息
- 生成更准确的词语表示
- 提高模型的语义理解能力
应用领域
- 自然语言处理:
- ELMo等模型使用情境嵌入
- 在机器翻译中提高准确性
- 改善文本分类和情感分析效果
- 图像处理:
- 结合图像的位置信息
- 整合RGB值与空间位置
- 创建更丰富的特征表示
- 多模态应用:
- 结合文本和图像信息
- 生成跨模态的嵌入表示
- 提升模型的理解能力
通过情境嵌入,我们可以更好地处理语言和图像的复杂性,使模型能够理解更细微的语义差异和上下文关系。这种技术在现代机器学习系统中发挥着越来越重要的作用。